
前言
梳理我学习 Rust 时的一些感受和体验。
因为 Rust 的语法和 C++ 区别非常大,所以有时候经常陷入混乱,特别是当我同时使用 Rust/C++/Golang/Zig 编码时,尤其前段时间为了发布 文档站 我又捡起 Next/Typescript 做了很多工作,各种语法在脑子里糊成一团了。
所以突然想,从头整理一遍,或许也有一定的意义。
对我自己肯定有意义。
当对于看官你嘛,那就取决于你了。
由于我是一个深度 C++ 患者,所以各种不适需要调整。也因此,这个重新梳理的所得,这篇文章,也算得上典型的致初学 Rust 的 C++ 程序员的对口说明。
Rust 字符串管理以及操作
几种字符串表达方式
正统的字符串表达方式有两种:String 和 &str。它们被用于变量声明。
字符串字面量,是一种常量,它总是被编译器抽出来归入初始化数据区,在可执行文件中单独被设置一个区段置于尾部,在可执行文件被加载到内存中时,这个区段被装入一个内存中的只读区段。足够智慧的编译器能够将字面量划分为两个或更多的子分区,其中一个是可丢弃的,即当 app 运行到一个特定点之后(一般是 c0startup 即将交递控制权给 main 时 ),这个可丢弃区段的内存区段就被释放。
我们也会顺便讨论相近的一些形态,如 Vec<char> 等。
&str
Rust 的字符串管理,令 C++/C#/Kotlin 程序员不适。
因为它的互操作特性着实隐晦而且繁琐。
当你有一个字符串字面量时,赋初值给一个变量,你会得到一个 &str,但是,实际上这是一个 &'static str,没错,这个生命期声明式的语法着实令人费解,尽管多数人都死记硬背,而且告诉自己习惯了就好,但加上 &'a str 和 &'_ str 呢?前者表示一个动态的生命期,带有标识符 a,所以所有生命期同名的变量被编译器隐含地当作有同样的截止期。而后者代表有一个生命期,但并不那么关心,纯粹是为了语法需要——做过编译器,我是指实用型编译器而非课程上的玩具,的人会明白,一个新语言要能设计的自洽且完美,基本上是不可能的,尤其是当你赋予它众多现代编程语言的特性时。
目前看来,也只有 C 保持了相当的语法层面的完美性,但代价是它的确有点简陋了。而像 C#/Kotlin/Swift 作为当代语言的执牛头者(语法层面),都有各色奇怪难解的部分显得丑陋。至于次一阶级的语言,Zig/Rust 等等,则难看的地方太多了。至于 Golang,就没必要提了,三教九流之外还有一档叫做不入流,就是为它而设的。
哦,对了,继续说那个变量:
1
2
3
4
let a: &str = "hi";
let b = "you"; // = &str or &'static str
_ = a
_ = b
这没什么特别的,重点是,如果 let mut a,并不意味着这个字符串能够被修改,这个声明只是让 a 可变,即,a = "you"; 能够让 a 指向一个新的只读形态的字符串。
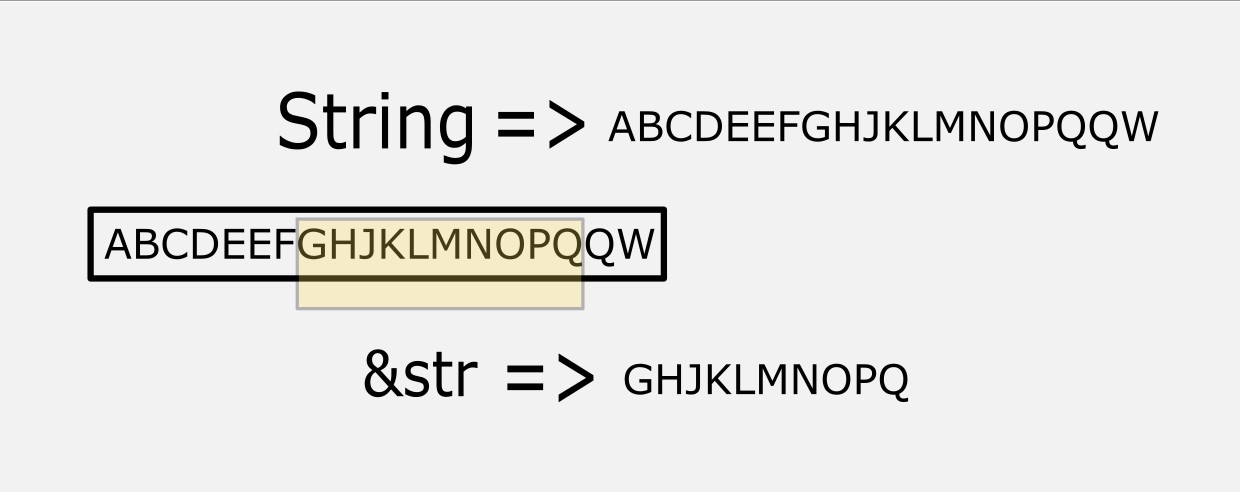
所以,&str 是一个指向字符串的指针。其目标可以是只读的(程序初始化数据区),也可以是动态的(即 heap 上分配空间的可被修改的字符串)。
精确点说,&str 是一个不可变参考,指向一个 UTF-8 字符序列的缓冲区。你不能使用一个 &str 变量来修改目标位置的字符串,即使它指向的目标实质上是一个 heap 的可变字符串对象;此时你只能使用那个 String 对象的变量来操作和修改字符串本身。
String
那么顺理成章的下一个问题,可被修改的字符串怎么声明?
1
2
3
4
5
6
7
let da: String = "hi".into();
let db = String::from("you");
let dc: String = a.to_string(); // from a `&str`
let dd = a.into();
let de = a.clone().to_string(); // make a clone
let df = "hi".to_string(); // also got a String
println!("{}, {}, {}, {}, {}\n", da, db, dc, dd, de, df);
这里展示了从字面量得到 String 声明的方法,以及从一个 &str 转换为 String 的方法。
当使用
into()时,需要指明目标变量类型String,编译器才能完成推导。
反过来,从 String 得到 &str 只需要引用借用即可:
1
2
let ab = &*db; // got a `&str`
let db2 = &db; // got a `&String`
是不是“很有意思”?
其实我一直宣称厌烦 Rust,因为我对于那种救世主似的为你好的宣扬者只觉得可笑。如果有谁当我是个傻瓜,给我一个傻瓜套装,处处限制,那么我肯定会觉得其实它才是不是傻?!Rust 的引以为豪的借用所有权,实际上并没有什么有趣的东西,因为做过编译器的人对此习以为常,把这个东西暴露给使用者去解决,这不是现代编译器应该做的。
编译器的发展方向,是让开发者越发地自由表达,同时还能精确表达,绝非是给开发者添上镣铐,让他们跳舞,然后说“啊……你跳得真美!”。
所以为了得到 &str,你需要在 String 上前缀以 &* 借用,否则单个 & 借用只能得到正宗的 &String 借用目标。
说来这也不难理解,符合逻辑。只不过 &* 着实难看。当然,觉得难看还是因为 C/C++ 积习难改,这么一想,我也就心平气和了。
如果真心厌烦
&*,或者你可以使用as_str():
这样也是个办法。
进一步地,如果需要可变对象呢,那就需要 &mut str 类型,此时的语法就要更新为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#[test]
fn test_str() {
let mut db = String::from("you");
{
let ab = &*db; // got a `&str`
println!("ab: {}", ab);
}
let mut mab = &mut *db; // got a `&mut str`
let mut dc = String::from("her");
assert_eq!(mab, "you");
mab = &mut *dc;
assert_eq!(mab, "her");
println!("mab: {}", mab);
}
这段测试代码毫无用处,仅仅向你展示 &mut *a_str 这种语法。
String 是什么?&str 呢?
Rust 设计 String 管理一个内存 buffer 区,就像字节数组一样。
这一点很重要!
所以 String 的直接操作得到的都是基于 byte 的。例如 String::len() 返回的是缓冲区的字节尺寸。
而更重要的是,Rust 约束 String 中总是存放一个字符串字面量的 UTF-8 表示。
什么意思?即这块缓冲区中的字符串内容是以 UTF-8 方式编码的。
所以 String::len() 并不能得到字符串字面量的字符个数。为了取得字符个数,你需要采用 Chars 迭代器方式进行计数:
1
2
3
4
5
6
7
let da_chs = String::from("hi 世界");
let count = da_chs.chars().count();
println!("{}", count); // got '5'
println!("{}", da_chs.len()); // got '9', "hi ".len = 3, "世界".len = 6
let iter = da_chs.chars() // got a `Chars`: i.e., str::iter::Chars<'_>
_ = iter;
如上,da_chs.chars() 返回一个 str::iter::Chars<'_> 类型的迭代器,通过计算(实际上会得到优化,立即返回)其方法 .count() 会得到 utf-8 字符串的字符个数。
Vec<char>
前面解释了如何理解 String 和 &str,有时候,也可以用 Vec<char> 来表示一个 UTF-8 字符的数组。这种方式有时候可能有点用处,当你需要明确地有性能地操作 UTF-8 字符时,它的优势比较于 String 和 String::chars 为无需 utf-8 计算,简单地用数组下标就可以获取数组集合中的每个 utf-8 字符,如果直接在 String 上操作则难免需要 utf-8 库参与来辨识每个有效的 UTF-8 字符才能完成索引操作,有时候这种代价可能难以接受,而解决的办法就是从 String 上一次性地将字符串分解为 char 的数组 Vec<char>,然后后继的大规模的字符索引操作的性能就能得到提升了。
所以,相互转换的方式是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#[test]
fn test_strings() {
// &str and String
let static_str: &str = "hello";
let mut dyn_str: String = "hello, world".into();
_ = dyn_str;
dyn_str = String::from(static_str);
dyn_str.push_str(", appended str here.");
println!("{}, {}", static_str, dyn_str);
// Vec<char>
let vc1: Vec<_> = static_str.to_string().chars().collect();
let vc2: Vec<char> = vc1;
println!("vec<char> #2, {}", vc2.iter().collect::<String>());
let vc3_cloned = vc2.to_vec();
println!("vec<char> #3, {}", vc3_cloned.iter().collect::<String>());
let vc4: Vec<char> = dyn_str.chars().collect();
println!("vec<char> #4, {}", vc4.iter().collect::<String>());
}
咦?有点累了,不写了,请看代码自行理解。

收尾了。
后记
有关 Rust 字符串的操作的更多内容,敬请期待下一篇。
图片直接取自网络,此致。
其中,overlay_image 取自 Youtube 一个课程 String and &str | Learn Rust part 7。不给链接了,请自行去搜索——因为 ads 和内容链接的缘故,微信说我的文档博客站涉嫌非法诱导#$@!&*^$,我觉得吧,我也没指望过微信等等。
如何学习 Rust?
我的经验是,同时使用 vscode + rust-analyser 和 JetBrains RustRover。
前者有点简陋,但调试器比较稳定。
它的问题在于简陋,有的跳转会出现问题。此外一个 bug 是,时不时会抽风,正在编写的代码在存盘时会突然被替换为标准库相关代码,例如 String 的部分源码,此时代码文件处于修改状态,注意用 Meta-Z undo 一次,就能找回你的代码,然后再次存盘时就正常保存,而不至于丢失代码。如果你错误地再次存盘,那么正在编写的代码就丢了,由于没有 RustRover 的 Local History 机制能够进行找回,那么就是真的丢了,只能重写。
这个 bug 是 vscode 的问题。
当然,不精确地说,还是 rust 的 for vscode 的 plugin 的问题,未知的崩溃导致 vscode 进行了错误的缓冲区内容传输而毁坏了你的当前编辑缓冲区,所以接下来 undo 能够恢复上一个编辑缓冲区从而找回你原有的代码。
同样的 bug 在 Zig 开发时也有,只不过 Zig 开发中是 当存盘时,或者在
fmt上鼠标飘过或者点击时,你的代码会被 fmt 源码替代,又或者是其他 zig std 标准库源码。解决办法同样是立即 undo,然后存盘。
后者大部分情况下全都好用。但问题是其执行器和调试器不稳定,经常出现无法明示的意外崩溃。此外调试器中常常无法正确计算变量的值,所以变量数值查看会出现错误。
但 RR 的优点是有利于初学者学习。因为它的 AI 补全功能能够为你提示常见的补全片段,所以本文中提到的各种相互转换在 RR 中常常无需记忆可以无脑补全。只不过这个补全有时候偶尔也会不完全彻底可靠,因为少数情况下它会产生复杂的调用转换,而实际上可能只需要 &* 即可(只是一个特例,其他情形也有)。对于这个问题,本文就有用了。或者,你可以通过深度挖掘 Rust 程序设计教程以及相关的教科书来做到完全的语法概念理解,也就能发现那些冗余转换,从而给出正确的简化形式。
那么,两者混合起来,对于初学者就比较友善。
这是我个人的体验。皆因我的传统思维过于固化。
🔚

留下评论