杂谈
生活很不容易。本文原本是两个月前打算发的。但是最后换到今天才发放了。这是因为生活真的很艰难,这个冬天是我最冷的一个冬天,在北方没有暖气着实难捱,前几次发文基本应该都有感叹手脚都不听使唤,穿多少都无法暖和,小太阳其实跟不存在没多大区别,它无法让一个区间暖和起来,在快递点学到一招,那人放倒一个电视大小的纸箱,尾部放一个小太阳在里边,纸箱覆盖一些说不出来是棉还是什么的东西,然后脚和小腿都能伸进去,人坐在纸箱开口这边,腿上搭着像小毛毯似的物品,感觉上挺暖和的。可惜照搬不能,因为找不到合适的材料。
但是还不是熬过来了。
多年前也曾在北方呆过,房檐挂冰锥下来那种。但那一回没什么惧怕的,因为呆的是变电所,不但每个办公室每个房间暖气充足,食堂也热气腾腾,一碗即时的大妈亲手拉面,浇上浇头,再一个盘子一块巨大的排骨,肉奇多的那种,旁边是北方专属的蒜头,稀里呼噜的下去,根本不知道冷为何物。
但这个冬天不一样。
告诉你,新买的 5 斤冬被根本不够,还要盖上一床睡袋,下面用水暖电热毯,才能在没有暖气的北方过下来。外边呆不住也不怕,完全蹲被窝就是最后一招了。
冬天快结束时,又学到了新招,在屋子里面可以买小暖房封锁一小块区域,几个平方的那种,然后里边密封好再生小太阳,过一阵子就能让这块小房间来到个十几度甚至二十度。这方法我还要去了解下,不晓得麻烦不。
另外,几天前又收到了草韵辨体,而且有收到两个版本。现代的人真是幸福,我童年的时候这些古本听都没听说过,那时候,知道孙过庭书谱,手上有赵孟頫真草千字文的,数不出几个人来,大多数人顶多知道神策军碑——我倒不是在说柳公权不行,而是想说真正的孤本善本你连听说的门路都没有,哪里像现在这么丰富,唾手可得。
我学习编程的年代,哪里有什么学习材料。
所以才会说现在的10~20岁的人多么幸福啊,他们不能做出发明创造的话,对得起这么好的环境吗?哈哈,胡乱地说,胡乱地唱。不要当真。
并发和并行编程
在 C++17 及以前的规范中,并发与同步依靠的是 std::mutex 和 std::condition_variable 的组合体。
在操作系统中同步与互斥还会涉及到 critical section 和 semaphore,前者是 std::mutex 的另一种表现,后者需要使用 std::condition_variable 来达成。当然在 C++20 中提供了 std::counting_semaphore 和 std::binary_semaphore,这就是另一个话题了。下次再聊。
std::barrier 和 std::latch
这两个工具类出自于 C++20 之后。
它们的作用是建立内存屏障,以便多任务能够同步到一个公共时间点。
std::latch
具体地说,std::latch 基本上等同于 Golang 中的 sync.WaitGroup,它持有一个计数器,你应该给定一个初值,例如线程数量,然后递减计数器,当计数归零时则在同步点的阻塞就被释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#include <functional>
#include <iostream>
#include <latch>
#include <string>
#include <thread>
struct Job
{
const std::string name;
std::string product{"not worked"};
std::thread action{};
};
int main()
{
Job jobs[]{ {"Annika"}, {"Buru"}, {"Chuck"} };
std::latch work_done{std::size(jobs)};
std::latch start_clean_up{1};
auto work = [&](Job& my_job)
{
my_job.product = my_job.name + " worked";
work_done.count_down();
start_clean_up.wait();
my_job.product = my_job.name + " cleaned";
};
std::cout << "Work is starting... ";
for (auto& job : jobs)
job.action = std::thread{work, std::ref(job)};
work_done.wait();
std::cout << "done:\n";
for (auto const& job : jobs)
std::cout << " " << job.product << '\n';
std::cout << "Workers are cleaning up... ";
start_clean_up.count_down();
for (auto& job : jobs)
job.action.join();
std::cout << "done:\n";
for (auto const& job : jobs)
std::cout << " " << job.product << '\n';
}
在示例代码中,job 线程的 body 通过 work_done.count_down() 来递减计数器,而主线程是在 work_done.wait() 处阻塞,直到所有 jobs 都递减了计数器值,则计数归零,则该阻塞的同步点释放,主线程才会继续向下执行。
注意除了 wait() 之外,你还可以使用 work_done.arrive_and_wait(),这个接口将递减计数器 count_down() 与 wait() 合二为一了,取决于你的业务逻辑有时候可以直接使用这个接口来简化代码结构。
sync.WaitGroup
Golang 的 WaitGroup 有相同的表现,只不过它通过 wg.Add(n) 来设定计数器初值,同样地递减计数器(via wg.Done())直到归零时释放阻塞的同步点,效果没有任何区别。示例代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int) {
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second)
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1) // increase the internal counter
go func() {
defer wg.Done()
worker(i)
}()
}
wg.Wait() // the sync point here
}
std::condition_variable for c++17 and earlier
在 C++20 之前,没有 std::latch 怎么办呢?std::latch 其实只不过是一个语法糖,它是条件变量(condition_variable)的一种包装后的形式,实质上没有区别。我们知道条件变量一般是和 mutex(或者其他 lockable)一起工作的,假设你为条件变量设定一个初值,然后递减之,通过 wait_for/wait_until 就能够在计数器归零时触发动作。例如上面的示例代码可以用条件变量来改写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
std::mutex m;
std::condition_variable cv;
std::string data;
bool ready = false;
bool processed = false;
void worker_thread()
{
// Wait until main() sends data
std::unique_lock lk(m);
cv.wait(lk, []{ return ready; });
// after the wait, we own the lock.
std::cout << "Worker thread is processing data\n";
data += " after processing";
// Send data back to main()
processed = true;
std::cout << "Worker thread signals data processing completed\n";
// Manual unlocking is done before notifying, to avoid waking up
// the waiting thread only to block again (see notify_one for details)
lk.unlock();
cv.notify_one();
}
int main()
{
std::thread worker(worker_thread);
data = "Example data";
// send data to the worker thread
{
std::lock_guard lk(m);
ready = true;
std::cout << "main() signals data ready for processing\n";
}
cv.notify_one();
// wait for the worker
{
std::unique_lock lk(m);
cv.wait(lk, []{ return processed; });
}
std::cout << "Back in main(), data = " << data << '\n';
worker.join();
}
虽然不是一摸一样的重写,但意图是相同的。
而且采用条件变量能够获得更多的灵活性,例如当条件触发时,还可以执行一个预定义动作。在这里的示例中,这个预定义动作是一个 lambda 函数:
1
[]{ return processed; }
说到这里,那就要提及 std::barrier 了。
std::barrier
std::barrier 和 std::latch 是一样的,只是多了能够指定触发事件的能力。
所以,可以继续示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <barrier>
#include <iostream>
#include <string>
#include <syncstream>
#include <thread>
#include <vector>
int main()
{
const auto workers = {"Anil", "Busara", "Carl"};
auto on_completion = []() noexcept
{
// locking not needed here
static auto phase =
"... done\n"
"Cleaning up...\n";
std::cout << phase;
phase = "... done\n";
};
std::barrier sync_point(std::ssize(workers), on_completion);
auto work = [&](std::string name)
{
std::string product = " " + name + " worked\n";
std::osyncstream(std::cout) << product; // ok, op<< call is atomic
sync_point.arrive_and_wait();
product = " " + name + " cleaned\n";
std::osyncstream(std::cout) << product;
sync_point.arrive_and_wait();
};
std::cout << "Starting...\n";
std::vector<std::jthread> threads;
threads.reserve(std::size(workers));
for (auto const& worker : workers)
threads.emplace_back(work, worker);
}
它的输出可能形如这样:
1
2
3
4
5
6
7
8
9
10
Starting...
Anil worked
Carl worked
Busara worked
... done
Cleaning up...
Busara cleaned
Carl cleaned
Anil cleaned
... done
当然,std::barrier 还是多遍的。这个多遍的意思是指,它允许在一次同步之后再次设定新的同步点,此时所有线程会在新的位置阻塞,计数器也被复原,然后重复递减直到再次归零。在上面的例子里,第一个 sync_point.arrive_and_wait() 意味着每个线程在该位置递减计数器并阻塞,直到全部线程都 waked up 并执行到该点的时候,递减足够了,计数器归零了,所有线程才同时全部从该点的阻塞状态中释放并继续执行。此时,sync_point 的计数器也恢复初值,于是每个线程可以在第二个 sync_point.arrive_and_wait() 同步点重复上述过程,这就是第二遍的同步点。如是反复,你可以使用 sts::barrier 在多线程中制作 n 个同步点。
这有何作用呢?
对于分阶段的计算密集工作池来说,这可能是有用的。设想一个工作池中不断调度计算任务。每个计算任务首先载入输入数据的某一个分片,全部计算任务将会分担输入数据的所有分片,当分片全部载入成功时——这是第一个同步点——每个计算任务都进入计算过程,这就是第二个同步点,直到所有计算任务完成计算之后,它们都进入第三个阶段,将计算结果写出到输出数据区中,同样地所有计算结果分片写出完成后,第四个阶段是后处理过程,将所有计算结果分片混合和组织为单一汇总的计算结果。
这时候,std::barrier 毫无疑问就是最佳选择了。
同样地道理,std::barrier 也是条件变量的一种语法糖。没有它,例如在 C++17 及以前同样也能很好滴生活。
hicc::pool::conditional_wait
好,介绍一下我们的 hicc::pool::conditional_wait,它也有正式版本在 cmdr-cxx 库中,叫做 cmdr::pool::conditional_wait。我一直以来都是在 hicc 或者 design patterns-cxx 中试验这些工具,然后再考虑将稳定的版本移植到 cmdr-cxx 或者 undo-cxx, ticker-cxx 等等稳定的开源库中的。
广告结束,conditional_wait 是一个 std::condition_variable 的包装,旨在让你能够以更好的语义书写业务逻辑。
例如同样的等待全部线程到达一个同步点,可以写作:
1
2
3
4
5
6
7
8
9
10
11
conditional_wait_for_int _cv_started{};
// run all theads
std::async(std::launch::async, []{
_cv_started.set();
// ok, here all threads are alive.
});
// and wait for all of them are alive
_cv_started.wait();
那么,conditional_wait 的实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
// conditional_wait, ...
namespace hicc::pool {
/**
* @brief a wrapper class for using std condition variable concisely
* @tparam T any type holder
* @tparam Pred a functor with prototype `bool()`
* @tparam Setter a functor with prototype `void()`
* @see hicc::pool::conditional_wait_for_bool
* @see hicc::pool::conditional_wait_for_int
*/
template<typename T, typename Pred = std::function<bool()>, typename Setter = std::function<void()>>
class conditional_wait {
Pred _p{};
Setter _s{};
protected:
std::condition_variable _cv{};
std::mutex _m{};
T _var{};
public:
explicit conditional_wait(Pred &&p_, Setter &&s_)
: _p(std::move(p_))
, _s(std::move(s_)) {}
virtual ~conditional_wait() { clear(); }
// conditional_wait(conditional_wait &&) = delete;
// conditional_wait &operator=(conditional_wait &&) = delete;
CLAZZ_NON_COPYABLE(conditional_wait);
public:
/**
* @brief wait for Pred condition matched
*/
void wait() {
std::unique_lock<std::mutex> lk(_m);
_cv.wait(lk, _p);
}
const bool ConditionMatched = true;
/**
* @brief wait for Pred condition matched, or a timeout arrived.
* @tparam R _Rep
* @tparam P _Period
* @param rel_time a timeout (std::chrono::duration)
* @return true if condition matched, false while not matched.
* >> false if the predicate pred still evaluates to false after
* the rel_time timeout expired, otherwise true.
*
* @details blocks the current thread until the condition
* variable is woken up or after the specified timeout duration.
*/
template<class R, class P>
bool wait_for(std::chrono::duration<R, P> const &rel_time) {
std::unique_lock<std::mutex> lk(_m);
return _cv.wait_for(lk, rel_time, _p);
}
bool wait_for() { return wait_for(std::chrono::hours::max()); }
/**
* @brief wait_until causes the current thread to block until the
* condition variable is notified, a specific time is reached,
* or a spurious wakeup occurs, optionally looping until some
* predicate is satisfied.
* @tparam C Clock
* @tparam D Duration
* @param timeout_time
* @return false if the predicate pred still evaluates to false
* after the timeout_time timeout expired, otherwise true. If
* the timeout had already expired, evaluates and returns the
* result of pred.
*/
template<class C, class D>
bool wait_until(std::chrono::time_point<C, D> const &timeout_time) {
std::unique_lock<std::mutex> lk(_m);
return _cv.wait_until(lk, timeout_time, _p);
}
bool wait_until() { return wait_until(std::chrono::time_point<std::chrono::system_clock>::max()); }
/**
* @brief do Setter, and trigger any one of the wating routines
*/
void set() {
// dbg_debug("%s", __FUNCTION_NAME__);
{
std::unique_lock<std::mutex> lk(_m);
_s();
}
_cv.notify_one();
}
/**
* @brief do Setter, trigger and wake up all waiting routines
*/
void set_for_all() {
// dbg_debug("%s", __FUNCTION_NAME__);
{
std::unique_lock<std::mutex> lk(_m);
_s();
}
_cv.notify_all();
}
void clear() { _release(); }
T const &val() const { return _value(); }
T &val() { return _value(); }
protected:
virtual T const &_value() const { return _var; }
virtual T &_value() { return _var; }
virtual void _release() {}
};
template<typename CW>
class cw_setter {
public:
cw_setter(CW &cw)
: _cw(cw) {}
~cw_setter() { _cw.set(); }
private:
CW &_cw;
};
class conditional_wait_for_bool : public conditional_wait<bool> {
public:
conditional_wait_for_bool()
: conditional_wait([this]() { return _wait(); }, [this]() { _set(); }) {}
virtual ~conditional_wait_for_bool() = default;
conditional_wait_for_bool(conditional_wait_for_bool &&) = delete;
conditional_wait_for_bool &operator=(conditional_wait_for_bool &&) = delete;
protected:
bool _wait() const { return _var; }
void _set() { _var = true; }
public:
void kill() { set_for_all(); }
};
class conditional_wait_for_int : public conditional_wait<int> {
public:
conditional_wait_for_int(int max_value_ = 1)
: conditional_wait([this]() { return _wait(); }, [this]() { _set(); })
, _max_value(max_value_) {}
virtual ~conditional_wait_for_int() = default;
conditional_wait_for_int(conditional_wait_for_int &&) = delete;
conditional_wait_for_int &operator=(conditional_wait_for_int &&) = delete;
inline int max_val() const { return _max_value; }
protected:
inline bool _wait() const { return _var >= _max_value; }
inline void _set() { _var++; }
private:
int _max_value;
};
}
两个简化形式 conditional_wait_for_bool 和 conditional_wait_for_int 是正常编码时推荐使用的工具类。
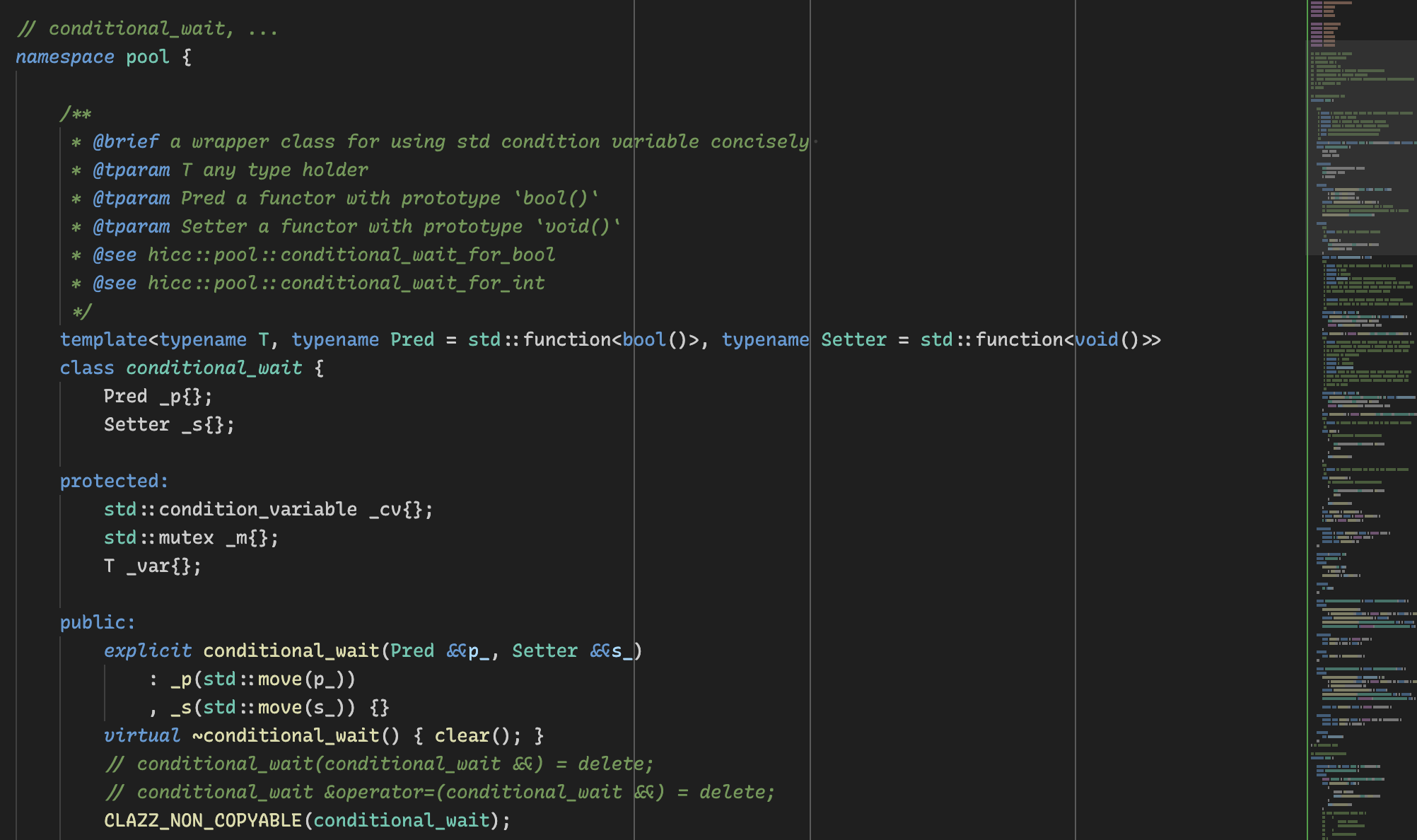
conditional_wait 是基于 C++17 的,所以通用性略强于 std::barrier 和 std::latch。它目前的唯一缺点是缺乏 std::barrier 的多遍同步点能力,好在这个能力的适用场景也往往很专一和狭窄,所以也许也算不得什么缺点。
cxx17 thread pool
在这篇旧文里主要介绍了为 hicc 和 cmdr 设计的专属线程池,它具有固定大小,提前建立工作线程,等待用户调度工作任务到池中,属于像数据库连接池、或者工作任务线程池这样的概念。
也可以设计和实现可变大小的,直到用户提交任务时才调度一个 OS 线程运行的古典线程池。也可以设计实现采用协程的协程池,当然要么自行实现协程库、要么采用 C++20。至于通用编程概念中的 WorkerPool,ResourcePool,ConnectPool,TaskPool/JobPool,Scheduler,Executor 等等,也只是万变不离其宗而已。
同样道理,可以将其改写为使用 std::barrier 方式,没有难度,略过。
后记
放飞自我时间到!
哦对了,今次开了一回引子所以尾巴上就不放飞了。
REFs
- hedzr.com: cxx17 thread pool
- hedzr/hicc: hicc::pool::conditional_wait
- hedzr/cmdr-cxx: cmdr::pool::conditional_wait
- std::barrier
- std::latch
- sync.WaitGroup
🔚
]]>