
Intro: 在 Web Server、TCP 通讯、API 交互等领域中,速率限制,Rate Limit,一般是面向请求次数、流量等参数进行速率控制。有的时候它又被称作流量控制。
Cover:
FROM: https://rafaelcapucho.github.io/2016/10/enhance-the-quality-of-your-api-calls-with-client-side-throttling/
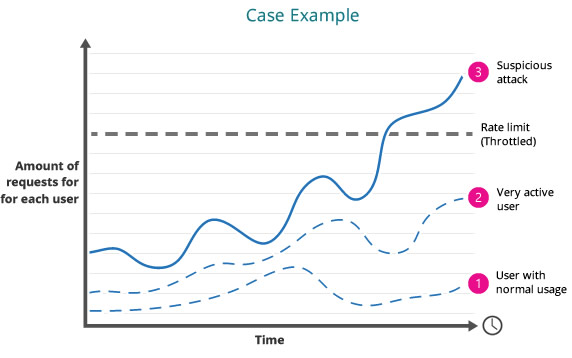
速率限制
在 Web Server、TCP 通讯、API 交互等领域中,速率限制,Rate Limit,一般是面向请求次数、流量等参数进行速率控制。有的时候它又被称作流量控制。
谈论流量控制时,大抵上要考虑到如下两个方面:
- 恒定速率(Constant Bit Rate,CBR)
- 变速速率(Varible Bit Rate,VBR)
这并不是 TCP 通讯专有的概念。事实上,速率控制是个跨越多学科存在的通用概念。例如在音视频播放时(特别是在流媒体播放时),解码速率也是需要被控制的:如果硬件的视频缓冲区速率不够,解码就要等等;如果流数据获取的太慢,也会导致解码停滞——但在这时候,播放却不可以暂停/或者至少声音不可以停顿。此时同样涉及到流控问题。
除了流控的速率问题之外,Rate Limit 最重要的一个设计与编码因素是进项流量的可抛弃性。
对于 TCP 底层的带宽控制和流控来说,流量是不准许被抛弃的,相反,TCP 协议强制要求保证包的可达性。所以在TCP协议中反而会为失败包做重传。
在微服务网关中,出于为下游服务提供平滑稳定的服务请求的目的,流控可能被要求是不可抛弃的,此时流控会摊平峰值请求到更长的时间片中,降低下游的瞬时功率。
不过,对于提供公众 API 服务的厂商来说,他们会在服务网关中加入限流逻辑,如果你尝试发出高频请求,那么这些请求中越限的部分将被网关抛弃,网关内部的下游服务不会见到这部分越限请求。
所以流控与限流相似也不相似,你需要明确区分他们。
但在 Rate Limiter 的设计过程中,是可以在一个软件组件中同时提供这两者的,只是需要设计者时时清醒就行。
实现方案
为了下面的论述方便,我们以每秒钟100次(100 r/s)请求作为速率限制的指标。
计数器方式
反应在脑海里的关于速率限制的实现方案,首先自然会是计数器法。它很简单明了,假定你有一个 counter,初值为 100,每次请求则 counter 减 1,直到 counter 为零时才根据条件(例如时间已经超过了 1s)重置为初值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
type counter struct {
Maximal int
Period time.Duration
count int
tick int64 // in nanosecond
}
func (s *counter) Take(count int) bool {
if time.Now().UnixNano() > s.tick {
// if timeout, reset counter regally at first
s.count = 0
s.tick = time.Now().Add(s.Period).UnixNano()
}
s.count += count // it's acceptable in HPC scene
return s.count <= s.Maximal // it's acceptable in HPC scene
}
计数器法的显著特点是缺乏均匀性。也就是说若在计时周期之中突发大批量请求时,Take() 也许仍会成功(只要计数器尚未超标)。但很显然,此时被准许的一批请求实际上是过于频繁,超标的。
这种情形下我们的限流规则尚且算是符合。但当在计时周期末尾,以及下一个计时周期开始时,如果分别进入了大量的请求,尽管这些请求仍被通过了,但我们的限流规则实际上已经被打破了:如果我们考察的周期以前一计时周期的中点开始到下一周期的中点的话,这一段时间内所通过的请求数可能达到我们的限流规则的两倍。
有时候,计数器法被表述为固定窗口法(Fixed Window),这和滑动窗口(Sliding Window)是相对应的。你可以将计数器法中的时间范围(也即案例中的1s)称作 1s 的统计窗口、或者计算窗口、或者观察窗口。
Sliding Log
有时候,Sliding Log 法被单列为一种算法。
此时大家认为它是和滑动窗口有所不同的一种方法:它将消费者请求按照时间戳进行序列化存储,并追踪这个序列。在一个请求进入时,此前的一组时间戳序列将被求和,这个 Sum 值与相应的 Duration 相除就能得到这一段时间内的请求频率。如果频率太高则请求被拒绝,否则则通过。为了尽可能节省内存,系统只保留一定容量的时间戳记。
但在我们看来,Sliding Log 实际上只是滑窗法的一种特定实现方案。
滑动窗口法
前文的讨论已经介绍到,要想解决计数器法的不平滑问题,我们需要更细的时间片粒度。不过,这显然是不怎么容易的。一方面,高精度时钟受制于硬件设施的不同,支持的力度也大不相同。另一方面,多细的粒度才叫细呢,1ms,还是 1ns,这是个问题——不同的场景对此可能会有不同的想法。
所以我们还需要更换一下思考角度,为了求得细腻的时间片,改用滑动窗口的方式来间接达到任意时间片粒度。
所谓滑动窗口法,实际上是指在请求发生时,向前检查一个观察窗口(例如 1s)的时间片,如果这段时间内的已经接纳的请求数尚未超标,就通过请求,反之拒绝。这样,无论请求以何种速率到来,我们始终在请求点向前的一个计时周期中做速率限制检测,这个时间片是随着请求点而推移的,所以我们将其称作滑动窗口。
滑动窗口是在计算机科学中被广泛应用的一个通用概念。例如在 LZW(LZ77)压缩算法中,字符串匹配中,TCP 通讯流控等等场景都有滑窗出没。
滑窗法的算法思路很容易理解。
但对于速率限制场景来说,它的编程实现并不容易,因为要想向前追踪和统计任意窗口已授权请求数,其内务计算量也不小。
我们已经知道可以存储每次请求的时间戳记(Sliding Log 法),然后按时钟方向反向求和来确定新请求是否已经越限。这是一种行得通的法子。如果你在做一个高吞吐量的 API Server,它的存储和计算代价可能也不小。
另一种方法是,将时间片窗口硬性划分为 8 个小片(pieces),分别记录每个小片中的已授权数,当新请求到来需要做滑窗内追踪时,只需要固定向前计算8个小片的累计和即可。这样可以大幅度降低计算量、内存消耗量,但是也就算是滑窗法的粗糙版:至少比较于计数器法精细度有大幅度提高。
对于高频交易来说,在速率限制这一任务上消耗大量的CPU或内存是不可接受的。所以生产环境中未必会采用滑窗思路落地到代码实现上。
漏桶法(Leaky Bucket)
基本原理
任意窗口中,已经授权的请求数不容易获取、或者计算量偏大,既然如此,我们可以反其道而行:假设一个恒定容量(100 滴水)的水桶接水,水龙头出水的速率取决于请求的多少,而水桶下方有一开口,正好能以 10ms 的速率匀速出水。那么无论进入的请求有多少,他们被这个水桶以特定的方式所约束,始终最多只能有等同于水桶容量的请求能被放过。
如果请求量过量,水龙头出水过多,则水桶溢出,这些多余的请求就被抛弃了。
如果不想抛弃溢出的请求,那么一般是采用自旋的方式等待水桶不满,然后再提交请求,直到所有请求都被放过,这就是以时间为代价做放过了。换句话说,我们找个足够大的额外的桶吧溢出的水接下来,然后重新送到水龙头上去滴水好了。
如此,我们就得到了速率限制的水桶思维版:漏桶法。
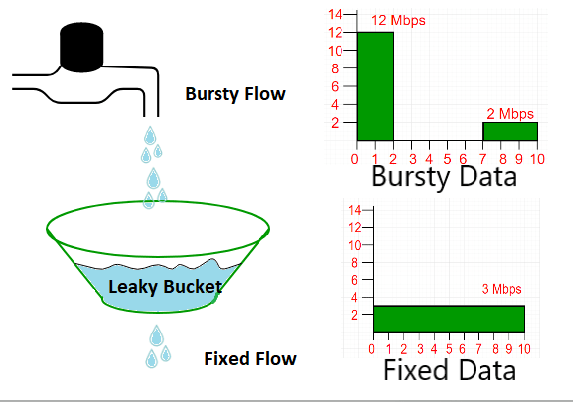
From: https://dev.to/swyx/networking-essentials-rate-limiting-and-traffic-shaping-43ii
根据出水策略的不同,非匀速的进入请求只要被准许,则可以被原样放出,或者是被整形后以恒定的速率放出(例如每 10ms 放出一个请求)。
很明显,如果不想抛弃多余的请求,那么你必须保证一段时间内的总请求量不会超过速率限制。否则这些阻塞的请求会造成瓶颈问题。
开源实现
在很多开源实现方案中,漏桶法被限定为古典式,也就是所谓的匀速出水模式(又称作带流量整形 Traffic Shaping 的漏桶算法)。
这类实现中,采用的是速率计算算法,典型的实现(例如 kevinms/leakybucket-go)可能是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
// Makes it easy to test time based things.
var now = time.Now
// LeakyBucket represents a bucket that leaks at a constant rate.
type LeakyBucket struct {
// The identifying key, used for map lookups.
key string
// How large the bucket is.
capacity int64
// Amount the bucket leaks per second.
rate float64
// The priority of the bucket in a min-heap priority queue, where p is the
// exact time the bucket will have leaked enough to be empty. Buckets that
// are empty or will be the soonest are at the top of the heap. This allows
// for quick pruning of empty buckets that scales very well. p is adjusted
// any time an amount is added to the Queue().
p time.Time
// The index is maintained by the heap.Interface methods.
index int
}
func NewLeakyBucket(rate float64, capacity int64) *LeakyBucket {
return &LeakyBucket{
rate: rate,
capacity: capacity,
p: now(),
}
}
func (b *LeakyBucket) Add(amount int64) int64 {
count := b.Count()
if count >= b.capacity {
// The bucket is full.
return 0
}
if !now().Before(b.p) {
// The bucket needs to be reset.
b.p = now()
}
remaining := b.capacity - count
if amount > remaining {
amount = remaining
}
t := time.Duration(float64(time.Second) * (float64(amount) / b.rate))
b.p = b.p.Add(t)
return amount
}
在上面的实现中,Add() 返回 0 表示水桶已满,也即请求获准失败。
它的实现稍微有些不利于我们按惯性去理解。
此外,uber-go/ratelimit 实现的就是完整的漏桶法匀速出水方案,为了做到匀速出水,在它的 Take() 中以阻塞方式进行检测,除非到达 10ms 边界,否则不会返回,从而达到了精确的匀速出水。由于涉及到的每个请求的状态量有多个,因此 uber 使用了 unsafe.pointer 的原子操作,这就使得其代码不是那么直观。所以我们没有在这里列举它的实现代码。
我们的版本
这类古典算法有时候也许并不是特别好的选择。他们的问题在于在请求进入时会在 Take() 处被阻塞,如此一来入口处可能产生请求堆积而无法有效地抛弃多余请求。进一步的表现为防 DDOS 能力较差。当然,其好处在于,只要生产场景要求的是进入请求不准许被抛弃,那么它们将被有效地堆积直到下游服务最终吃进,这样的特性对于微服务削峰是恰当的。
非阻塞实现
根据这些实作上的认识,我们另行实现了一套漏桶算法(完整 repo),允许提供非阻塞入口方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
func New(maxCount int64, d time.Duration) *leakyBucket {
return (&leakyBucket{
int64(maxCount),
make(chan struct{}),
int64(d) / int64(maxCount),
time.Now().UnixNano(),
0,
}).start(d)
}
type leakyBucket struct {
Maximal int64
exitCh chan struct{}
rate int64
refreshTime int64 // in nanoseconds
count int64
}
func (s *leakyBucket) Count() int64 { return atomic.LoadInt64(&s.count) }
func (s *leakyBucket) Available() int64 { return int64(s.count) }
func (s *leakyBucket) Capacity() int64 { return int64(s.Maximal) }
func (s *leakyBucket) Close() {
close(s.exitCh)
}
func (s *leakyBucket) start(d time.Duration) *leakyBucket {
if s.rate < 1000 {
log.Errorf("the rate cannot be less than 1000us, it's %v", s.rate)
return nil
}
// fmt.Printf("rate: %v\n", time.Duration(s.rate))
// go s.looper(d)
return s
}
func (s *leakyBucket) looper(d time.Duration) {
// nothing to do
}
func (s *leakyBucket) max(a, b int64) int64 {
if a < b {
return b
}
return a
}
func (s *leakyBucket) take(count int) (requestAt time.Time, ok bool) {
requestAt = time.Now()
s.count = s.max(0, s.count-(requestAt.UnixNano()-s.refreshTime)/s.rate*int64(count))
s.refreshTime = requestAt.UnixNano()
if s.count < s.Maximal {
s.count += int64(count)
ok = true
}
return
}
func (s *leakyBucket) Take(count int) (ok bool) {
_, ok = s.take(count)
return
}
func (s *leakyBucket) TakeBlocked(count int) (requestAt time.Time) {
var ok bool
requestAt, ok = s.take(count)
for !ok {
time.Sleep(time.Duration(s.rate - (1000 - 1)))
_, ok = s.take(count)
}
time.Sleep(time.Duration(s.rate-int64(time.Now().Sub(requestAt))) - time.Millisecond)
return
}
在这套实现方案中,利用 Take() 的无阻塞效果,你可以有以下的自定义选择:
- 首先你要通过非阻塞的 Take() 尝试获得准许
- 如果未能获准通过:
- 如果你不想抛弃请求,则自行建立一个 queue 来缓存和延后重新尝试获得准许。
- 如果你需要抛弃越限请求,那么什么都不做好了
- 对于获准的请求,在 Take() 返回后得到的是不经过匀速整形的出水。
兼容于 uber-go/ratelimit
不过,如果你是在制作一份用于削峰目的的 rate limiter 中间件的话,你可能还是希望像 uber 那样的效果:不抛弃未获准请求,且匀速出水。这没有关系——尽管有点粗劣——我们还是提供了一份阻塞版本 TakeBlocked(),它能够让获准请求匀速流出。以测试函数为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import "github.com/hedzr/rate/leakybucket"
func TestLeakyBucketLimiter(b *testing.T) {
var counter int
l := leakybucket.New(100, time.Second, false) // one req per 10ms
defer l.Close()
time.Sleep(300 * time.Millisecond)
prev := time.Now()
for i := 0; i < 20; i++ {
ok := l.TakeBlocked(1)
now := time.Now()
counter++
fmt.Println(i, now.Sub(prev))
prev = now
time.Sleep(1 * time.Millisecond)
}
b.Logf("%v requests allowed.", counter)
}
运行后的结果是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
$ go test -v -race -test.run='^TestLeakyBucketLimiter$' ./leakybucket
==== RUN TestLeakyBucketLimiter
0 9.468477ms
1 10.47512ms
2 12.589327ms
3 10.364861ms
4 11.820381ms
5 10.353834ms
6 12.504309ms
7 10.167151ms
8 11.623466ms
9 10.487361ms
10 10.72498ms
11 12.435839ms
12 11.73813ms
13 10.956558ms
14 11.893156ms
15 11.964504ms
16 11.856545ms
17 11.094344ms
18 10.978074ms
19 10.632583ms
lb_test.go:36: 20 requests allowed.
--- PASS: TestLeakyBucketLimiter (0.53s)
PASS
ok github.com/hedzr/rate/leakybucket 0.957s
而如果没有能够获准时,该请求将会一直阻塞下去,直到下一次获取成功——由于rate=10ms(即1000ms/100次)的约束的存在,所以阻塞也不会超出 rate 边界太多。
虽然不那么精确,也很有点拙劣,但是我们弄了一个,对吧。
面向 Public API - 简化的 Gin 中间件
如果要建立 Public API 的场景的话,越限请求(尤其是恶意的请求)必须是被抛弃的,这时候 uber 的 ratelimit 版本就不合适了,此时非阻塞版本才是恰当的选择。
一个简化的 gin 中间件可以这样来写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
func (r *Limiter) getRL(ctx gin.Context) rateapi.Limiter {
if r.limiter == nil {
r.limiter = leakybucket.New(100, time.Second, false)
}
return r.limiter
}
func (r *Limiter) SimpleMiddleware() gin.HandlerFunc {
return func(ctx *gin.Context) {
limiter := r.getRL(ctx)
if err != nil {
ctx.AbortWithError(429, err)
} else if limiter != nil {
if limiter.Take(1) {
ctx.Writer.Header().Set("X-RateLimit-Remaining", fmt.Sprintf("%d", limiter.Available()))
ctx.Writer.Header().Set("X-RateLimit-Limit", fmt.Sprintf("%d", limiter.Capacity()))
ctx.Next()
} else {
err = errors.New("Too many requests")
ctx.Writer.Header().Set("X-RateLimit-Remaining", fmt.Sprintf("%d", limiter.Available()))
ctx.Writer.Header().Set("X-RateLimit-Limit", fmt.Sprintf("%d", limiter.Capacity()))
ctx.AbortWithError(429, err)
}
} else {
ctx.Next()
}
}
}
按照约定俗成的标准,被抛弃的请求会得到 response header 通知:
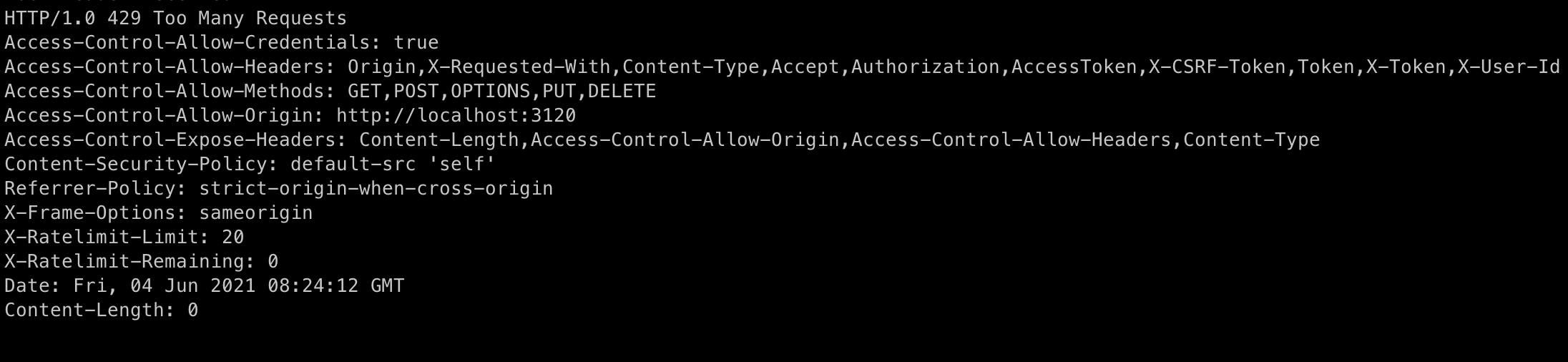
Gin 中间件
作为上述简化代码的完善版本,我们提供了一个 gin ratelimit 中间件,你可以直接取用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import "github.com/hedzr/rate/middleware"
func engine() *gin.Engine {
r := gin.Default()
r.Use(middleware.NewLimiterForGin(time.Second, 100, func(ctx *gin.Context) (string, error){
key := ctx.Request.Header.Get("X-API-KEY")
if key != "" {
return key, nil
}
ctx.JSON(403, gin.H{"code": 2901, "message": "API key is missing"})
return "", errors.New("API key is missing")
}))
return r
}
在示例中,你提供一个 keygenFunc 给中间件,这个函数应该返回一个唯一的 key,例如某个 API Client 所申请得到的 API KEY,然后中间件就会为这个 key 单独维护一个 rate limiter。
根据你的业务场景,你可以选择更恰当的 keygenFunc 因子。比方说不是在检测 X-API-KEY header,而是检测 header 中的 X-USER-TOKEN,或者以 IP/GeoIP 为 key 的依据,那么我们可以获得对特定用户、不同IP、特定地区的限流政策。
当然,在 HPC 场景,你可能还需要在我们提供的这个中间件的基础上进一步地拓展,例如对大规模 API KEYs 场景你需要有分区分节点的措施、以防止单个节点上的大量 rate limiters 导致内存溢出,等等。
而一旦采用了多节点分布式计算策略时,你更需要改造和采用分布式的 ratelimit 核心算法——我们所提供的完整 repo并不直接支持分布式计算场景。
令牌法(Token Bucket)
漏桶法面向进入请求进行整形(去掉多余的,仅获准者被漏下),但是它虽然是我们面对滑窗难以编码而转换的新思路,却和滑窗的差异略大。
所以令牌法才是更接近滑窗法思路的调优算法。
总的来说,我们假设一个 producer 以恒定速率(每 10ms 一个)制造令牌,而一个请求被获准时则消耗一块令牌。如此一来,单位时间片中已经授权了多少请求就不再是重点,重点现在变为令牌桶中有否可用令牌的问题。
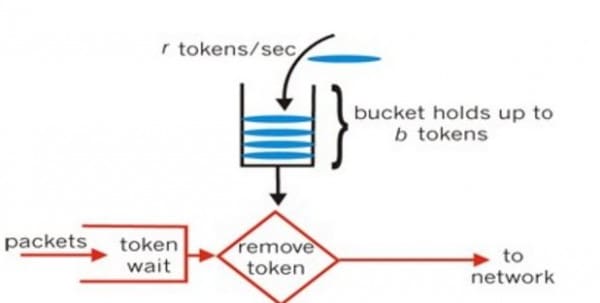
From: https://dev.to/swyx/networking-essentials-rate-limiting-and-traffic-shaping-43ii
由于令牌总是被匀速制造的,所以进入请求会被均匀地限流(也就是在 10ms 周期的所有多余的请求都不被获准),令牌法比较于前面几种方法来说在这个领域有绝对优势。
反过来说,如果进入请求不可以被抛弃的话,令牌法就会带来额外的阻塞开销:未能获准的请求需要在一个更慢的队列中(或者直接就地阻塞的方式)重试直到获取到令牌而通过时为止。
于是我们有这样的实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
func New(maxCount int64, d time.Duration) *tokenBucket {
return (&tokenBucket{
int32(maxCount),
d,
int64(d) / int64(maxCount),
make(chan struct{}),
int32(maxCount),
}).start(d)
}
type tokenBucket struct {
Maximal int32
period time.Duration
rate int64
exitCh chan struct{}
count int32
}
func (s *tokenBucket) Count() int32 { return atomic.LoadInt32(&s.count) }
func (s *tokenBucket) Available() int64 { return int64(s.count) }
func (s *tokenBucket) Capacity() int64 { return int64(s.Maximal) }
func (s *tokenBucket) Close() {
close(s.exitCh)
}
func (s *tokenBucket) start(d time.Duration) *tokenBucket {
if s.rate < 1000 {
log.Errorf("the rate cannot be less than 1000us, it's %v", s.rate)
return nil
}
go s.looper(d)
return s
}
func (s *tokenBucket) looper(d time.Duration) {
ticker := time.NewTicker(d / time.Duration(s.Maximal))
// fmt.Printf("token building spped is: 1req/%v\n", d/time.Duration(s.Maximal))
defer func() {
ticker.Stop()
}()
for {
select {
case <-s.exitCh:
return
case <-ticker.C:
vn := atomic.AddInt32(&s.count, 1)
if vn < s.Maximal {
continue
}
vn %= s.Maximal
if vn > 0 {
atomic.StoreInt32(&s.count, s.Maximal)
}
}
}
}
func (s *tokenBucket) take(count int) bool {
if vn := atomic.AddInt32(&s.count, -1*int32(count)); vn >= 0 {
return true
}
atomic.StoreInt32(&s.count, 0)
return false
}
func (s *tokenBucket) Take(count int) bool {
ok := s.take(count)
return ok
}
func (s *tokenBucket) TakeBlocked(count int) (requestAt time.Time) {
requestAt = time.Now().UTC()
ok := s.take(count)
for !ok {
time.Sleep(time.Duration(s.rate - (1000 - 1)))
ok = s.take(count)
}
// time.Sleep(time.Duration(s.rate-int64(time.Now().Sub(requestAt))) - time.Millisecond)
return requestAt
}
在我们的这份实现中,与漏桶法相似地支持了一些高级特性,例如支持非阻塞或者阻塞版本,等等。Line 76 目前被我们注释掉了,因为暂时我们不希望在 Token Bucket 算法中做匀速出水的额外处理:事实上,由于令牌本身的产出是均匀的,所以在除开一些边界条件的其它多数情况中,我们直接就能获得相对均匀的出水。而加上 Line 76 的效果只是相对更加均匀而已,我认为这不一定是必须的。
其它特性
在我们的令牌桶实现中,由于已经做了算法抽象,所以在漏桶法中已经描述过的特性,可以毫无障碍地改为令牌桶法。具体来说,使用我们的 rate 组件的方式是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package main
import (
"fmt"
"github.com/hedzr/rate"
"time"
)
func main() {
// rate.LeakyBucket, rate.TokenBucket, ...
l := rate.New(rate.LeakyBucket, 100, time.Second)
for i := 0; i < 120; i++ {
ok := l.Take(1)
if !ok {
fmt.Printf("#%d Take() returns not ok, counter: %v\n", i, rate.CountOf(l))
time.Sleep(50 * time.Millisecond)
}
}
}
与其相似地,在 web server 框架中以中间件的方式使用我们的 rate 组件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import (
"github.com/hedzr/rate"
"github.com/hedzr/rate/middleware"
)
func engine() *gin.Engine {
config := &middleware.Config{
Name: "A",
Description: "A",
Algorithm: stirng(rate.TokenBucket),
Interval: time.Second,
MaxRequests: 1000,
HeaderKeyName: "X-API-TOKEN",
ExceptionKeys: nil,
}
r := gin.Default()
rg := r.Group("/api")
rg.Use(middleware.ForGin(config))
// ...
config2 := ...
r.Post("/login", middleware.ForGin(config2), loginHandler)
return r
}
如果你也在采用我们的 cmdr,middleware.LoadConfig("server.rate-limites") 或者 middleware.LoadConfigForGin("server.rate-limits", rg) 还可以进一步简化你的代码编写。
对 looper 做增强
在 looper() 的实现方法中,我们采用了一个匀速 producer 来生产令牌。
考虑到更多潜在的限流策略可能性,在这里实际上可以考虑采用变速方案。一些典型的可能性有:
- logN 或者 ln 加速器方案
- 平滑变比匀速:以一个时间片为统计单位,时刻调整 rate 值,从而在突发流量消耗了大部分令牌之后,降低今后一段时间的令牌发放速度。在 Google Guava 中它被称为 SmoothBusrty。
- 平滑预热匀速:又被称作 SmoothWarmUp。在一个时间片的前一部分时间里以较快速度发放较多令牌,此时发放令牌的速度呈现出负加速度;随后,剩余时间内剩余令牌以匀速放出。
- 其它更多方式:取决于具体的生产场景,可以通过定制 looper 算法来提供更多的策略(示例代码中未予以实现)。
值得注意的是,令牌法不但思路易于理解,代码实现也极其容易。不仅如此,令牌法的运行开销也差不多在各类实现中是最小的。
在开源实现中,juju/ratelimit 同样地实现了令牌桶算法。
比较
在前面的思考中,我们已经提到了各个算法的一些特点。
在本文范围内,最后的一点时间,姑且简单总结一下几种典型算法的异同:
- 计数器方式:最容易实现,但应变能力最差,效率较高
- 滑动窗口法:理论易于理解,即尽可能地缩小计量粒度,从而将计数器的应变能力平滑地提高。然而很难以代码高效实现。
- 漏桶法:较好的取舍,针对进项流量进行整形,(通常)以匀速放出流量。
- 令牌法:相对最优的取舍,针对出口进行整形,(通常或可选地)以近似匀速放出流量。非常容易拓展为针对业务场景进行整形定制。
取决于进项流量可否被抛弃,在 ratelimit 实现时要注意采用恰当的方法:
- 考虑是否采用异步方式(另行处理被抛弃流量)/ 非阻塞模式(由调用者自行处理被抛弃流量)
- 异步方式不适用于 API 接口的限流场所或者用作 web server middlerware
- 异步方式、或者非阻塞方式有最好的进项流量接收性能
- 非阻塞模式或阻塞方式的选择
在我们的实现代码 https://github.com/hedzr/rate 中,对于阻塞方式没有做最优化处理,所以出口并不精确。如果你对这部分代码异常感兴趣,最佳的源码参考在:
- 漏桶:https://github.com/uber-go/ratelimit
- 令牌:https://github.com/juju/ratelimit
TODO
这一篇中,略微提及了 HPC 中的 Rate Limit 问题。不过,详细讨论它需要另行着墨了。
在这里我们可以提前做简短的介绍:
- HPC 场景中,速率限制需要被分布式地实现
- 在特定的分布式场景中,分布式的速率限制可以考虑被提升到入口点(通常可能是负载均衡器,或者是 Microservice API Gateway 处)去同一个处理。
- 即使是由 API GW 处理,依然是一个分布式的速率限制器。
参考
- https://github.com/uber-go/ratelimit
- https://github.com/juju/ratelimit
- https://github.com/kevinms/leakybucket-go
- https://github.com/hedzr/rate
- https://en.wikipedia.org/wiki/Bandwidth_management
- https://en.wikipedia.org/wiki/Token_bucket
- https://en.wikipedia.org/wiki/Leaky_bucket
- Networking Essentials: Rate Limiting and Traffic Shaping - DEV Community 👩💻👨💻
- Scaling your API with rate limiters
- How To Design A Scalable Rate Limiting Algorithm
- NGINX Rate Limiting
🔚


留下评论