
Git Clone 的多种方法
按照下载量的大小以及 repo 的完整程度,Git Clone 实际上有很多种方法。下面依次列举一下。
Normal Clone
传统的 Clone 取回远程仓库的一切内容。这种方法通常被使用,下载量也是最大的。
以 LLVM 项目的源码仓库而言,当前的全仓尺寸大约 4.3GB 上下(其中 .git 目录的本地磁盘空间占用为 2.2GB左右,working directory 本体大约 2.1GB 的样子),一次完整的标准 Clone 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ git clone https://github.com/llvm/llvm-project
Cloning into 'llvm-project'...
remote: Enumerating objects: 6540723, done.
remote: Counting objects: 100% (4544/4544), done.
remote: Compressing objects: 100% (1492/1492), done.
remote: Total 6540723 (delta 3982), reused 3053 (delta 3052), pack-reused 6536179 (from 3)
Receiving objects: 100% (6540723/6540723), 2.02 GiB | 3.16 MiB/s, done.
Resolving deltas: 100% (5417295/5417295), done.
Updating files: 100% (157588/157588), done.
$ du -sh llvm-project llvm-project/.git
4.3G llvm-project
2.2G llvm-project/.git
$
这显然还是很有压力的。
如果你的镜像选取的不好,那么遇到 EOF 错误的几率相当高,由于 git clone 不能支持断点续传(这毕竟不是单一对象,.git 下面的数据对象(blob)实际上是以数据库记录的形态组织的),所以每次 EOF 都会导致整个 clone 过程重启,对于像 linux-project, llvm-project 等等这样的大仓库来说,完成首次 clone 几乎成为不可能的事情。
.git 中存储的内容可以被划分为 blob, index 等等几大类,我们已经提及这些内容实际上构成了一个数据库,git 提交历史所形成的版本记录实际上被映射为数据库的表记录。
所以当你需要完整的数据库的时候,各方面的压力均无法轻易释放。
Shallow Clone
所以最典型的轻量级克隆方法是 Shallow Clone。
这种方法的特点是仅下拉给定 refspec (通常为 HEAD)的相关记录,而放弃一切的其它 branches(以及 tags)。
对于那种分支和 release tags 奇多的大仓库来说,Shallow Clone 的效果立竿见影,能够显著降低下载量。
同样以 LLVM 为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ git clone --depth=1 https://github.com/llvm/llvm-project llvm-project-shallowed
Cloning into 'llvm-project-shallowed'...
remote: Enumerating objects: 165365, done.
remote: Counting objects: 100% (165365/165365), done.
remote: Compressing objects: 100% (139258/139258), done.
remote: Total 165365 (delta 36896), reused 61531 (delta 21641), pack-reused 0 (from 0)
Receiving objects: 100% (165365/165365), 243.62 MiB | 6.37 MiB/s, done.
Resolving deltas: 100% (36896/36896), done.
Updating files: 100% (157588/157588), done.
$ du -sh llvm-project-shallowed llvm-project-shallowed/.git
2.3G llvm-project-shallowed
280M llvm-project-shallowed/.git
$
尽管我们观察到下载量的绝对值依然不小(总体大约 280MB),但这比全仓下载的 2.2GB 已经是巨大的改善了,粗略而论的话已经提速了十倍。
相对于很多代码仓库的 5MB 或者数十 MB 而言,280MB 可以算是一个大数值了。
注意,单论下载量的话,我们只需要考虑 .git 文件夹的尺寸即可,因为 working directory 中的文件都是通过从 .git 记录中解包而得来,并不被计算在下载量中。
Unshallow
当完成了浅克隆之后,我们得到了一个单层的本地仓库,单层表示提交记录,Tree 记录,都只有单一的条目,而不是带有历史的,交叉参考的。
所以此时采用 git log 的话将无法查看版本提交历史记录。
要想查看历史记录,则需要 Unshallow 操作:
1
$ git fetch --unshallow
它将会触发拉回全部的历史记录以及相关对象。
操作完成之后,你将会得到一个完整的本地仓库,一切都和正常的 git clone 获得的仓库是等价的。
这也意味着,你需要保证你的网络质量了。
Lite unshallow
如果想要稍微轻量级一点的 Unshallow,也不是没有办法,下面的指令可以尝试:
1
$ git fetch --unshallow --filter=blob:none
它的作用是略过 blobs 对象的下拉,通常这会大幅度节省下载量。
与该命令的核心思想相同的是在 git clone 时就略过 blob 对象,这种方法也被成为 blobless clone,下面将予以介绍。
Blobless Clone
所谓的 Blobless Clone,就是指在所有下拉行为中都跳过 blobs 对象。
由于 blobs 对象实质是仓库中工作文件的文件内容,所以大多数情况下这意味着大权重的下载数据量因此而得到节省。正因为对 blobs 对象的略过不会影响到 trees 和 commits 的下载,所以在本地仓库中 git log 将会是完整有效的。
同样地原因,既然没有下拉文件内容 blobs,所以在本地仓库中就不会复原出工作文件拷贝。这一点值得注意:这种情况与 bare repo 是不同的,因为这样的本地仓库相比较于 bare blob 缺失了 blobs 实体。
当你在这样的 blobless 仓库中开始进一步操作时,涉及到的 blob 对象将被自动触发并从 remotes 拉取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
$ git clone --filter=blob:none https://github.com/llvm/llvm-project llvm-project-blobless
Cloning into 'llvm-project-blobless'...
remote: Enumerating objects: 4361826, done.
remote: Counting objects: 100% (3285/3285), done.
remote: Compressing objects: 100% (1195/1195), done.
remote: Total 4361826 (delta 2853), reused 2095 (delta 2090), pack-reused 4358541 (from 3)
Receiving objects: 100% (4361826/4361826), 602.63 MiB | 13.54 MiB/s, done.
Resolving deltas: 100% (3430550/3430550), done.
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), done.
Total 1 (delta 0), reused 1 (delta 0), pack-reused 0 (from 0)
remote: Enumerating objects: 152470, done.
remote: Counting objects: 100% (113697/113697), done.
remote: Compressing objects: 100% (99085/99085), done.
remote: Total 152470 (delta 29815), reused 14612 (delta 14612), pack-reused 38773 (from 3)
Receiving objects: 100% (152470/152470), 238.48 MiB | 1.52 MiB/s, done.
Resolving deltas: 100% (36789/36789), done.
Updating files: 100% (157590/157590), done.
$ du -sh llvm-project-blobless llvm-project-blobless/.git
3.1G llvm-project-blobless
1.0G llvm-project-blobless/.git
$
blobless 的速度较慢,这是因为 git clone –filter=blob:none 的时候实际上做了两步: git fetch 和 git checkout。在 fetch 的时候 blob 的确被放弃了,但当 checkout 的时候,为了建立工作拷贝的文件,相关的 blob 不得不被下载回来。所以 git clone –filter=blob:none 节约的份额又被消费了一部分,造成了现在的后果。
很容易想到,如果 bare clone 的话,是不是就能完整地节约了?
blobless + Bared
的确如此。所以下面做出了示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
$ git clone --filter=blob:none --no-checkout https://github.com/llvm/llvm-project llvm-project-blobless-bared
Cloning into 'llvm-project-blobless-bared'...
remote: Enumerating objects: 4361890, done.
remote: Counting objects: 100% (3368/3368), done.
remote: Compressing objects: 100% (1220/1220), done.
remote: Total 4361890 (delta 2910), reused 2164 (delta 2139), pack-reused 4358522 (from 3)
Receiving objects: 100% (4361890/4361890), 599.79 MiB | 14.07 MiB/s, done.
Resolving deltas: 100% (3431888/3431888), done.
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), done.
Total 1 (delta 0), reused 1 (delta 0), pack-reused 0 (from 0)
$ du -sh llvm-project-blobless-bared llvm-project-blobless-bared/.git
742M llvm-project-blobless-bared
742M llvm-project-blobless-bared/.git
$
注意看,如果 checkout 工作拷贝的话,.git 中额外需要下载的 blob 对象大约为 300MB(1.1GB-742MB)。
Shllowed + blobless + bared
通过限制历史记录(commits 乃至于 trees)的下拉层级为单层(--depth=1),可以启用浅拷贝机制,这会限制 commits 和 trees 对象的下载量。
将它和前面的 blobless 叠加起来可以进一步削减下载量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
$ git clone --depth=1 --filter=blob:none --no-checkout https://github.com/llvm/llvm-project llvm-project-blobless-bared-shallowed
Cloning into 'llvm-project-blobless-bared-shallowed'...
remote: Enumerating objects: 12897, done.
remote: Counting objects: 100% (12897/12897), done.
remote: Compressing objects: 100% (10124/10124), done.
remote: Total 12897 (delta 70), reused 8154 (delta 55), pack-reused 0 (from 0)
Receiving objects: 100% (12897/12897), 5.15 MiB | 1.68 MiB/s, done.
Resolving deltas: 100% (70/70), done.
$ du -sh llvm-project-blobless-bared-shallowed llvm-project-blobless-bared-shallowed/.git
6.6M llvm-project-blobless-bared-shallowed
6.6M llvm-project-blobless-bared-shallowed/.git
$
成果斐然,对吧?
没什么好说的,这几乎已经够用了。
然而,这种方法的坏处是 git log 没法查看,你只能在 unshallow 之后才能查看 log 和提交历史。
为了让 unshallow 也轻量级,下面对其加上了 --filter=blob:none。
这种做法对于 Code Reviewers 通常是够用的,他们多数时候不必关心文件的完整内容而只需要查看变更的 lines 就足够了,所以 blobs 对他们来讲大多数情况下是无需在本地变现的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
$ cd llvm-project-blobless-bared-shallowed
$ git fetch --unshallow --filter=blob:none
remote: Enumerating objects: 4261444, done.
remote: Counting objects: 100% (4261435/4261435), done.
remote: Compressing objects: 100% (816018/816018), done.
remote: Total 4253079 (delta 3360725), reused 4247089 (delta 3354878), pack-reused 0 (from 0)
Receiving objects: 100% (4253079/4253079), 548.78 MiB | 14.85 MiB/s, done.
Resolving deltas: 100% (3360725/3360725), completed with 3841 local objects.
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), done.
Total 1 (delta 0), reused 1 (delta 0), pack-reused 0 (from 0)
remote: Enumerating objects: 12, done.
remote: Counting objects: 100% (12/12), done.
remote: Compressing objects: 100% (12/12), done.
remote: Total 12 (delta 0), reused 12 (delta 0), pack-reused 0 (from 0)
Receiving objects: 100% (12/12), 4.21 KiB | 2.11 MiB/s, done.
From https://github.com/llvm/llvm-project
* [new tag] llvmorg-10-init -> llvmorg-10-init
* [new tag] llvmorg-11-init -> llvmorg-11-init
* [new tag] llvmorg-12-init -> llvmorg-12-init
* [new tag] llvmorg-13-init -> llvmorg-13-init
* [new tag] llvmorg-14-init -> llvmorg-14-init
* [new tag] llvmorg-15-init -> llvmorg-15-init
* [new tag] llvmorg-16-init -> llvmorg-16-init
* [new tag] llvmorg-17-init -> llvmorg-17-init
* [new tag] llvmorg-18-init -> llvmorg-18-init
* [new tag] llvmorg-19-init -> llvmorg-19-init
* [new tag] llvmorg-20-init -> llvmorg-20-init
* [new tag] llvmorg-21-init -> llvmorg-21-init
$ git log --oneline
f37c24194e2b (HEAD -> main, origin/main, origin/HEAD) [Clang] Set the final date for workaround for libstdc++'s `format_kind` (#140831)
2d956d2d4ecd [flang] fix ICE with ignore_tkr(tk) character in explicit interface (#140885)
dc29901efb18 [AMDGPU] PromoteAlloca: handle out-of-bounds GEP for shufflevector (#139700)
d36028120a6e [flang] add -floop-interchange and enable it with opt levels (#140182)
2cf6099cd5fa [NFC][Support] Apply clang-format to regcomp.c (#140769)
fb627e39e28a [LLVM][IR] Replace `unsigned >= ConstantDataFirstVal` with static_assert (#140827)
b5e3d8ec084d [LLVM][TableGen] Use StringRef for various members `CGIOperandList::OperandInfo` (#140625)
a7ede51b556f [mlir][XeGPU] Add XeGPU Workgroup to Subgroup Distribution Pass (#140805)
...
$ cd ..
$ du -sh llvm-project-blobless-bared-shallowed llvm-project-blobless-bared-shallowed/.git
697M llvm-project-blobless-bared-shallowed
697M llvm-project-blobless-bared-shallowed/.git
$
所以上面也展示了相应的后续步骤。此时 –depth=1 带来的优势就基本上被抵消了。
但是,由于 shallow clone 能够加速形成本地副本,所以这种分两步走的方法有时候对于抽象的网络条件仍然是具备意义的。
Treeless Clone
Trees 对象代表着工作拷贝的目录结构关系和文件名信息,所以你也可以省去对其的下载,从而更进一步地降低下载量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
$ git clone --filter=tree:0 --no-checkout https://github.com/llvm/llvm-project llvm-project-treeless-bared
Cloning into 'llvm-project-treeless-bared'...
remote: Enumerating objects: 552618, done.
remote: Counting objects: 100% (23/23), done.
remote: Compressing objects: 100% (23/23), done.
remote: Total 552618 (delta 1), reused 10 (delta 0), pack-reused 552595 (from 4)
Receiving objects: 100% (552618/552618), 193.18 MiB | 13.17 MiB/s, done.
Resolving deltas: 100% (8873/8873), done.
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), done.
Total 1 (delta 0), reused 0 (delta 0), pack-reused 0 (from 0)
$ du -sh llvm-project-treeless-bared llvm-project-treeless-bared/.git
225M llvm-project-treeless-bared
225M llvm-project-treeless-bared/.git
$ cd llvm-project-treeless-bared && git log --oneline && cd ..
... (ignored)
大多数情况下,blobless 和 treeless 两者任选其一已经足以改善你的下载质量了。
值得注意的是,当前 git 不支持同时应用 blobless 和 treeless 的 filters 条件。
By size
--filter 还可以指定其它条件,例如限制 blob 不能超过 1MB:--filter=blob:limit=1m。
完整的 --filter 说明,可以在下面的链接中找到:
Git - git-rev-list Documentation
By object type
git sparse-checkout 是一种较为轻量级的 checkout,它比 --no-checkout 温和一点,但没有 normally checkout 那么多,带上参数 --sparse 进行 git clone 即可。
下面的示例来自 GitLab 官方文档:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Clone the repo excluding all files
$ git clone --filter=blob:none --sparse [email protected]:gitlab-com/www-gitlab-com.git
Cloning into 'www-gitlab-com'...
remote: Enumerating objects: 678296, done.
remote: Counting objects: 100% (678296/678296), done.
remote: Compressing objects: 100% (165915/165915), done.
remote: Total 678296 (delta 472342), reused 673292 (delta 467476), pack-reused 0
Receiving objects: 100% (678296/678296), 81.06 MiB | 5.74 MiB/s, done.
Resolving deltas: 100% (472342/472342), done.
remote: Enumerating objects: 28, done.
remote: Counting objects: 100% (28/28), done.
remote: Compressing objects: 100% (25/25), done.
remote: Total 28 (delta 0), reused 12 (delta 0), pack-reused 0
Receiving objects: 100% (28/28), 140.29 KiB | 341.00 KiB/s, done.
Updating files: 100% (28/28), done.
$ cd www-gitlab-com
$ git sparse-checkout set data --cone
remote: Enumerating objects: 301, done.
remote: Counting objects: 100% (301/301), done.
remote: Compressing objects: 100% (292/292), done.
remote: Total 301 (delta 16), reused 102 (delta 9), pack-reused 0
Receiving objects: 100% (301/301), 1.15 MiB | 608.00 KiB/s, done.
Resolving deltas: 100% (16/16), done.
Updating files: 100% (302/302), done.
For more details, see the Git documentation for sparse-checkout.
| From: [Clone a Git repository to your local computer | GitLab Docs](https://docs.gitlab.com/topics/git/clone/) |
partial clone (no-checkout)
实际上,前面的示例中已经提前应用了 --no-checkout。
有的时候这个参数可能是 --bare,但是意义不变,都是起到不 checkout 本地工作文件的目的,从而得到的是一个 bared repo。
示例省略。
可能最快的 Clone
综合前面提到的各种方式,可以得到最快的 clone 方法应该是:不下载 blob 对象,不签出本地文件。相应的操作步骤大致如下:
1
2
3
4
5
6
#fastest clone possible:
$ git clone --filter=blob:none --no-checkout https://github.com/llvm/llvm-project llvm-blobless-bared
$ du -sh llvm-blobless-bared llvm-blobless-bared/.git
$ cd llvm-blobless-bared
$ git sparse-checkout init --cone
$ git read-tree -mu HEAD
完整的操作记录如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ git clone --filter=blob:none --no-checkout https://github.com/llvm/llvm-project llvm-blobless-bared
Cloning into 'llvm-blobless-bared'...
remote: Enumerating objects: 4362056, done.
remote: Counting objects: 100% (3418/3418), done.
remote: Compressing objects: 100% (1268/1268), done.
remote: Total 4362056 (delta 2964), reused 2156 (delta 2145), pack-reused 4358638 (from 3)
Receiving objects: 100% (4362056/4362056), 599.87 MiB | 16.26 MiB/s, done.
Resolving deltas: 100% (3432005/3432005), done.
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), done.
Total 1 (delta 0), reused 1 (delta 0), pack-reused 0 (from 0)
$ du -sh llvm-blobless-bared llvm-blobless-bared/.git
742M llvm-blobless-bared
742M llvm-blobless-bared/.git
$ cd llvm-blobless-bared
$
由于 git 自身的限制,因此你无法组合 blobless 和 treeless 条件,而上面列出的方法是当前评估下相对最快的 Clone 方法,最终获得的本地副本至少保证了 commits history 能够被有效地检索。
替换为 treeless
但是如果远程仓库中的文件内容不大,提交历史却超过万条甚至是数百万条,这时候 trees 对象的下载量就不应该忽视了,此时应该采用 treeless 的方式。
替换为 sparse checkout
如果你需要本地的工作文件副本,那么最快的 clone 是 shallow+sparse 方法:
1
2
3
4
5
6
7
#fastest clone possible:
$ git clone --filter=blob:none --sparse --depth=1 https://github.com/llvm/llvm-project llvm-sparse
$ du -sh llvm-sparse llvm-sparse/.git
$ cd llvm-sparse
$ git sparse-checkout init --cone
$ git read-tree -mu HEAD
$ git fetch --unshallow
它会尽快得到本地工作文件,但无法进行 git log 操作,直到你 unshallow 它为止。
背景知识
Blobs, Trees, Commits & Logs
Git 的实现机理中,四种基础对象按照它们承载的意义相互组织在一起,构成了我们所获得的版本历史的拼图;同时,这些基础对象按照适当的关系相互勾稽,也形成了我们所提及过的磁盘存储中的数据库结构。
理解上述的四种对象,可以直接阅读 ProGit Book 的 Git - Git 对象 章节。
其中的关系图比较有参考价值:
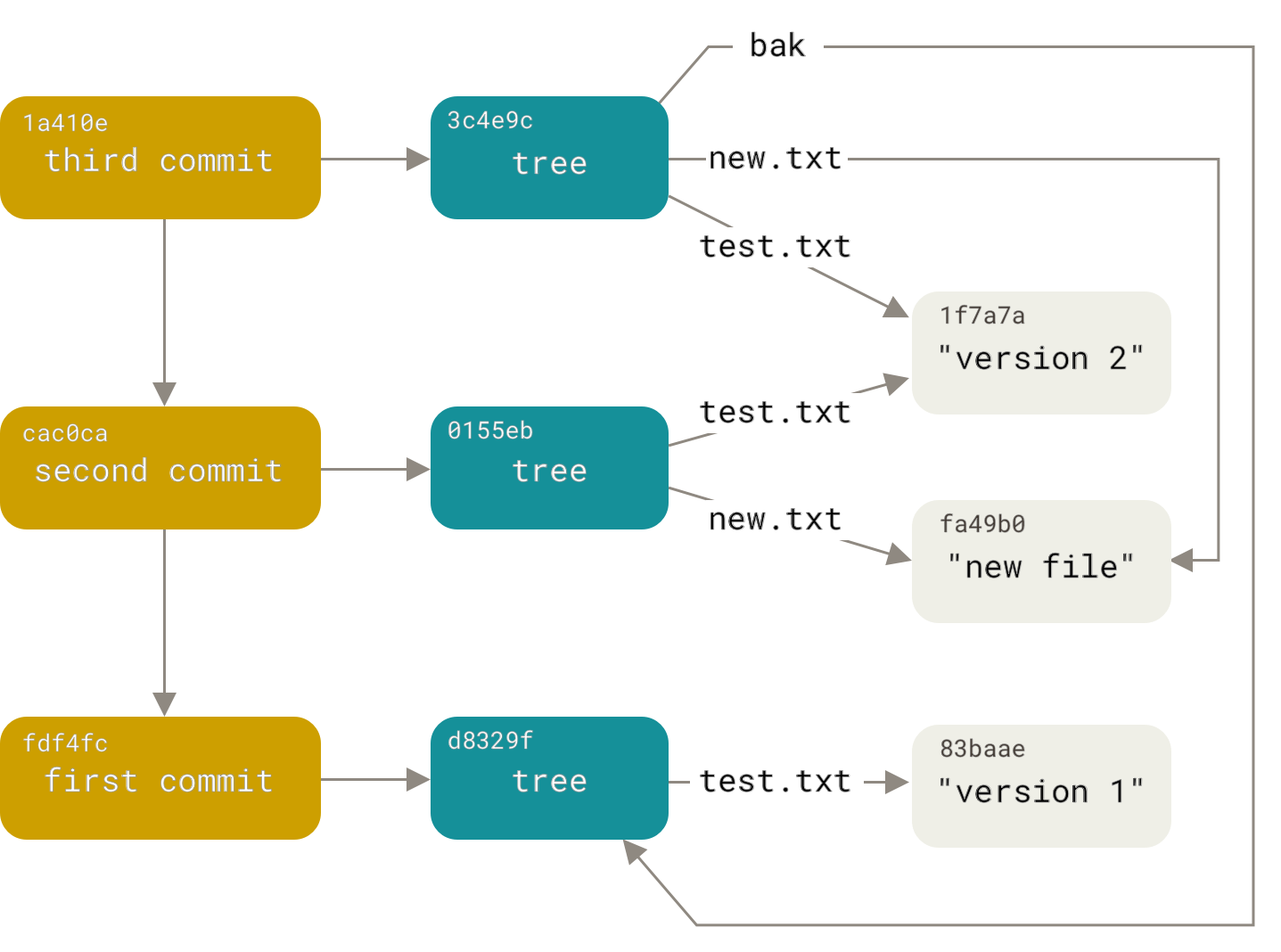
它展示了 commits, trees, filenames, blobs(file contents) 之间的逻辑组织关系。
Blobs 代表着每个工作文件的内容。
Trees 代表着文件夹名称和文件名称,同时也涵盖了文件夹层级结构。
Commits 对应着版本历史中的每一条提交记录,每个提交由一个唯一的 hash 串标识(本质上是一个针对该提交记录的 sha-1 摘要),hash 串被 base64 格式化后的长度 40 chars,通常取其前 6 或 8 位作为短语,从概率上说对于单一的仓库而言前 8 位足以唯一地识别 Commits 了,如 70460b。
Logs 是关联到每一 Commit 的日志信息,由 git log 予以呈现。
Refs 是在 Commits 历史上的特定位置的粘连的标记。通用地看,每个 hash 串都是一个 ref,此外诸如 branch,tags 等也都是某个提交的别名,也被视为 ref 的一种,并且有对应的逻辑名字,例如 refs/heads/master,refs/tags/v1.0.0,refs/remotes/origin/master 等等。这方面信息请阅读 Git Pro 的 Git - Git 引用 章节。
结束语
还有没有更快的方法?
的确还有一种:
使用你的 github 身份申请免费的 Azure Linux 主机,然后 SSH 进去做 git clone,秒速!
这样不但能够得到完整仓库,速度上的损失也没有多少。
但这种方法也有限制,因为免费主机的磁盘空间有限,所以太大的 repo 可能你还是无法下拉。
如果 clone 成功了,你可以 zip 那个目录,然后用 sftp 断点续传地下拉到本地在解压缩回来,这可能是最适合网络条件不稳的场所的方案。
🔚

留下评论