
HISTORY
0221 -
0226 -
0227 -
Preface
C++11 之后的异常(Exceptions)有大量的改变。但我们当然无法在一篇 post 中对此进行完全的回顾,所以本文中也只是针对特定需求进行讨论,并展示在 cmdr-cxx 中使用的 stack trace dumping 技术。
异常、中断和故障
C++ 异常
在 C++ 中,异常表示一种如何抛出错误、如何捕捉错误的程序设计框架。
C++ 通过 throw 抛出错误,这个错误可以是一个 int 数值,或者一个字符串常量,也可以是一个 C++ 类对象的实例(例如 std::runtime_error)。
C++ 通过 try{ ... } catch (std::runtime_error &e){ ... } catch(...){...} 这样的结构捕捉可能产生的错误。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <iostream>
#include <stdexcept>
int main(int argc, char* argv[]){
try{
if(argc<=1)
throw std::runtime_error("expect an arg");
return 0;
} catch(std::runtime_error &e) {
std::cout << e.what() << '\n';
exit(-1);
}
}
当你不带参数运行这个 app 时,它抛出一个 runtime_error 并且捕捉到它,然后 exit(-1)。
Intel CPU 中断和异常
CPU 层面的中断是一个打断当前指令执行流程的事件。外部设备通过硬件电路向 CPU 提交一个中断请求,CPU 则识别到这个请求,挂起当前流程,响应中断请求,恢复挂起的当前流程继续执行。这是 CPU 层面中断的原始定义。
随即,这一概念立即被扩展。除了外设之外,其他硬件层面的信号,不能继续的CPU指令(例如无效机器吗,被零除等等),软件代码预先设置的软件中断等都被纳入中断等大范畴中。它们的共性在于都要求(实时地或者非实时地)CPU挂起正在执行的流程,即中断现场,处理了中断请求之后返回该中断现场。所以在这个共性之下,CPU 层面也对此做了划分:即中断 Interrupt 和异常 Exception。
中断 Interrupt
中断是一种异步信号,中断信息立即跟随 CPU 时钟信号被传达到 CPU 内部。
中断又可以被细分为为 NMI(不可屏蔽中断) 和 INTR(可屏蔽中断),其中可屏蔽中断代表着不紧急的事件。
总的来说,对于 Intel 这样的非 RT 的 CPU,中断虽然是即时响应的,但并不具备严格意义上的实时性。这个方面不深入研究了。
异常 Exception
异常是一种同步中断,它的紧急性比中断还低,异常是在一条指令被执行结束后才被传入 CPU 内部的。而异常的处理也只能是在指令被执行完毕后才能获得调度。
可检测异常
可检测异常是一个大类,凡是在CPU执行指令期间硬件上发生的各类错误满足异常条件时,异常就会被产生,并等待被 CPU 处理。CPU处理完当前指令后,保存异常现场,然后调度异常处理程序去处理,在处理完毕后返回保存的现场继续执行下一条指令。
可检测的异常可以被细分:Fault,Trap 和 Abort。
Fault:可纠正异常。CPU 在执行完异常处理程序之后返回重新执行刚才到指令(而不是下一条)。
Trap:陷阱。通常意义上的异常。CPU 会返回执行下一条指令。
Abort:终止。发生了致命错误,CPU 不再执行当前保存的指令流,其所代表的进程被废弃。操作系统负责接管这类情形的善后工作:操作系统通过安装 abortion exception handler 来处理致命错误,它会将当前进程调度出局,然后继续调度其他排队中的进程到 CPU 中执行,如果没有,则调度 Shell 进程(通常是指 tty,GUI 系统中则是一个抽象概念)等待用户的输入。
编程产生的异常
通常是指 int 3 或者 int 21 这样的软中断,往往是由程序主动调用并发起的。
小节
上面简介了 C++ 层面的异常和 CPU 层面的异常。这是因为用户程序要正确恰当地处理意外的错误、意外的事件,必须对所谓的意外事件有充分的了解。
有的是该你做的,有的是不归你管的。
这个话题涉及到整体架构问题,所以一次也只能讲一点,很难纲目清晰地全面介绍,尤其是在一篇 post 里。
C++ 异常于编码上的考虑
业务层面
首先来说,我们需要知道现在(C++11以后)的异常 try…catch 机制。
现在对于 exception,不再模凌两可,而且强调一切异常都是 std::exception 或其派生类,所以理论上说我们只需要一个拦截:
1
2
3
4
5
try{
// ...
} catch(std::exception const& e) {
std::cout << "Caught: " << e.what() << '\n';
}
在很多时候,用 stdout 还是 stderr 是个挺折磨人的问题。由于我们认为再大的错误也很普通:),所以在我们的代码中,经常性地只会使用 stdout 来输出异常捕俘后的信息,而非 stderr。
业务逻辑错
所谓的业务层面,是指你正在编程想要办到的事情,也即 Java 领域中常常简称的业务逻辑。
通常,我们用 std::exception 及其派生类(例如 std::runtime_error)包裹的是业务层面的错误。例如各种意义上的业务逻辑错误,诸如密码位太短啦,密码位太长啦,用户名太长等等。
这些错误类似于 Intel CPU 的异常那样,也可以分为可恢复的,不可恢复的等等几种。例如密码位太短意味着我们将会等待用户重新输入一遍,而在登录验证处验证失败多次时则应该终止验证,记录非法IP等等。
所以我们可能会建立两个层次的异常拦截处理:
1
2
3
4
5
6
7
8
9
10
11
class biz_error: public std::runtime_error { ... };
int main(){
try{
...
}catch(biz_error const& e){
//...处理业务层的错误,必要时加入恢复逻辑
}catch(std::exception const &e){
//...提示错误位置供开发员诊断错误原因
}
}
其他错
C++ 标准现在提供 std::exception_ptr,它有点像 catch(std::exception const &e) 的扩展形式。之所以提供这种“指针”,是为了配合 catch(...) 使用的。官方的案例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#include <iostream>
#include <string>
#include <exception>
#include <stdexcept>
void handle_eptr(std::exception_ptr eptr) // 按值传递 ok
{
try {
if (eptr) {
std::rethrow_exception(eptr);
}
} catch(const std::exception& e) {
std::cout << "Caught exception \"" << e.what() << "\"\n";
}
}
int main()
{
std::exception_ptr eptr;
try {
std::string().at(1); // 这生成一个 std::out_of_range
} catch(...) {
eptr = std::current_exception(); // 捕获
}
handle_eptr(eptr);
} // std::out_of_range 的析构函数调用于此,在 ept 析构时
可以看到它的功能和 catch(const std::exception& e) 没有多大的不同,颇有点脱了裤子放屁的味道。但有时候它能提供一种更符合直觉的代码书写形式,理解起来可能会更容易。
非业务层面
被零除
像被零除这样的问题,一般来说被归类为非业务层面的异常。在 Intel CPU 的开发者手册中将其定为硬件级异常。这样的问题通常代表着开发员编码级别存在问题,所以我们需要对它们采用不一样的拦截方式。
简单地说,被零除将会导致一个 SIGFPE 信号被抛出,对于 POSIX 兼容的操作系统来说你可以拦截到这个信号。
但在 Windows 环境中情况会有所不同。在那里会有一个结构化异常。
稍后我们还会讲述更多一点背景知识。但现在我们只需要知道,这样的错误在 C++ 标准的异常体系中没有办法处理,所以我们需要另行包装才能解决问题。在 cmdr-cxx 中,针对 POSIX 环境有这样的工具提供以帮助你拦截被零除的错误:
1
2
3
4
5
6
7
8
9
10
t1 += sub_cmd{}("dbz", "dbz", "divide-by-zero")
.description("causes a segfault and hook it via linux signal()")
.group("Test")
.on_invoke([](cmd const, string_array const &) -> int {
// cmdr::debug::UnhandledExceptionHookInstaller _ueh{};
cmdr::debug::SignalInstaller<SIGFPE> _si{};
int foo = 0;
printf("%d\n", 8989 / foo); // causes segfpe
return 0;
});
拦截的目的在于,在故障发生时,我们可以获得一定的信息,以利于我们追溯到故障的发生位置,然后才能予以解决。
在上面的示例代码中,只有 line 6 值得关注,这一行安装了 SIGFPE 的拦截器,默认时会打印出堆栈信息,而 line 8 会产生一个被零除错误,并交给 SignalInstaller<SIGFPE> 去拦截和提取辅助信息。
运行它的结果部分截图是这样的:
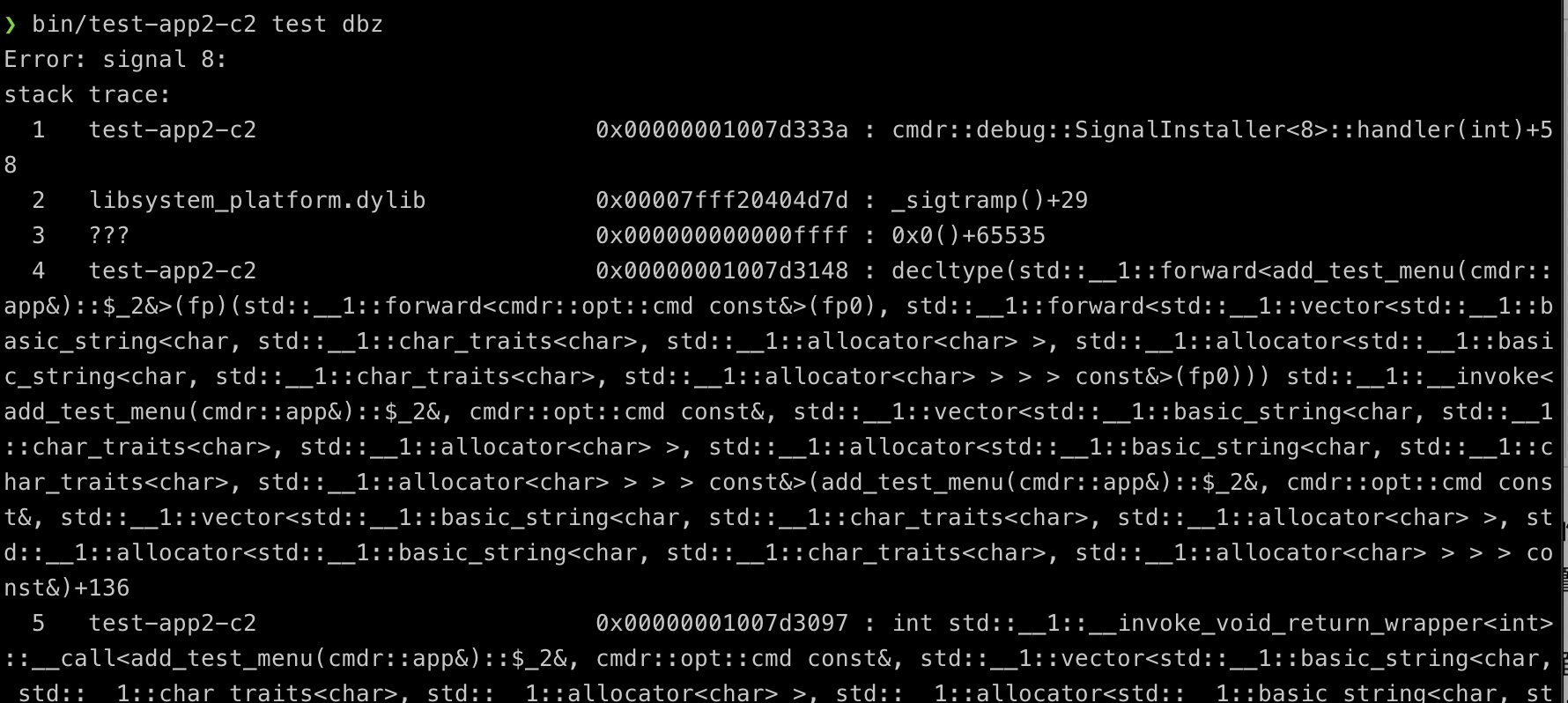
可以看到,尽管没有行号信息,但至少我们已经基本上可以定位得到故障点了。
这也是 C++ 代码中针对异常能够做到的最好的程度了。
如果这都不满意,那么你需要一个强力的 IDE,或者自行采用 gdb/lldb 等方式动态调试和追踪来暂停到产生异常到故障点。那样做是可行的,但也是不可行的,例如你的代码只在线上环境的特定场景中才会抛出异常,难不成还要挂着 remote debugger 去拦截吗?你愿意老板也不可能愿意,老板能忍最终用户也不能忍呀。
编译器优化
在 release 模式编译时,大多数编译器都会自动检测被零除的情况,这当然是有限的检测,它能够工作有赖于静态编译期求值。像上一小节的例子,在有的编译器中将会报出一个 warning,大抵就是说发现了被零除问题,最好改改。
因此,如果你真的需要,就要采用一点点技巧来避免这种警告。话说,警告又有什么关系呢,我知道很多人都是直接忽略的。但对我来说,消除警告仍然是有意义的,大型系统中,强制将警告当作错误有其现实意义,你不可能在成百上千的警告和错误混杂中有效地排除问题,尤其是你不会有精力去辨别什么是潜在有问题的警告,什么是确确实实的不恰当的编码。
所以说,实际上我们采用的是下面这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static auto i_foo = 1;
t1 += sub_cmd{}("dbz", "dbz", "divide-by-zero")
.description("causes a segfault and hook it via linux signal()")
.group("Test")
.on_invoke([](cmd const, string_array const &) -> int {
#if __clang__ || __GNUC__
// cmdr::debug::UnhandledExceptionHookInstaller _ueh{};
cmdr::debug::SignalInstaller<SIGFPE> _si{};
#endif
// int foo = 0;
printf("%d\n", 8989 / i_foo); // causes segfpe
return 0;
});
cli.set_global_pre_invoke_handler([](cmdr::opt::cmd const &, string_array const &) -> int {
i_foo = 0;
return 0;
});
静态变量 i_foo 在一个初始化 lambda 中被实际置为 0,就可以避免编译器警告了。这当然是因为我们需要这段代码来测试实际发生了零除错误时我们的拦截效果,所以它不是错误也不是有疑问的代码。这样做的好处在于,下一次编译时只要看到零除警告时我们就要当心了,因为那可能就真的是一个不恰当的编码所在。
关于 SIGFPE
说起来,POSIX 信号 SIGFPE 也是很有意思的一个家伙。因为当我们产生了被零除错误时,POSIX 系统要求将其翻译为 SIGFPE 然后递交到用户程序。然而 SIGFPE 是什么?SIGFPE 是 Signal Floating-point exception 的意思。不过实际上产生这个信号并不意味着你正在执行某种浮点运算,反而更为通用,它表示你在执行一个算术运算但发生了错误,被零除只是其中之一。有的系统中算术溢出也会导致 FPE,针对某些 Intel CPU,据说包括一些 IA-32 架构,INT_MIN 除以 -1 也会导致 FPE。
在 gcc 中,被零除很有可能会被编译器所优化,从而不再产生 FPE 信号,但你可以通过 gcc -o sigfpe sigfpe.c 开关来获取相关的警告信息且保证代码原样生成机器码,所以有时候也许你需要它。
理论上说,SIGFPE 可以由你手动地发送给你的程序:
1
2
3
4
5
$ ./test-app &
32771
$ kill -8 32771
Caught divide by zero
-8 表示我们想要发送 SIGFPE 信号。一般情况下我们使用 -9 强行结束进程时实际上我们是在发送 SIGKILL 信号。这一方面的知识请自行查找 POSIX 信号的有关资料。
然而我们也可以注意到,尽管手动发送 FPE 信号是行得通的,但事实上没有意义:首先,我们不可鞥将这个信号的拦截器改造成一个别的功用,因为那破坏了信号约定;其次,SIGFPE 属于 Fault 级别的硬件中断,什么意思?它意味着当拦截器处理了信号内容之后,指令执行会回到发生错误的原位置(比方说,也就是正在除以零的算式)再次执行,因为硬件层认为 Fault 是一种可恢复的错误,所以拦截器处理完 Fault 之后,硬件层可以重新执行导致 Fault 的语句,这隐含着拦截器已经修理了错误的约定。
所以当手动发送这个信号时,事实上并没有所谓的 Fault 现场供返回,那是个无意义的位置;其次来说,拦截器究竟是什么也不做就返回 Fault 现场呢,还是 exit 终止进程呢。对于用户程序来说,拦截器也是会两难的。
所以事实上我们都是在调试阶段发现被零除错误,然后解决错误,保证从理论到实践上都不可能再发生被零除错误。这才是我们通常所做的事。我们并没有必要依赖 SIGFPE 信号拦截器来做任何额外修理的必要性。
至于说编译期就解决的零除错误,那就不必在这一节中关注了。
null 指针非法访问等
Null 指针访问在大多数过程性开发语言中都是存在的,哪怕是 Java 这样的号称没有指针的语言也不能真正免除由它带来的困扰——甚至情况比 C/C++ 还要严重。
本质上说,Null 指针非法访问引发的是一种硬件级别障碍,因为像 Intel CPU 这样的基础架构中,低端内存是另有他用的,所以你在尝试使用一个指向这段地址的指针进行访问或者置值时就等于是违例了。
当然,除此而外,错误的指针使用还可能是不同类型的取出或置入,尝试对只读段写,尝试对已经交换出内存的位置读写,尝试读写超出本段范围的其他地址等等。在支持内存保护的 CPU 架构中,这一切都是非法指针的可能的表现形式。
总的来说,这些问题都会引发硬件级别的异常。
不同的操作系统都会管理这些问题,从而避免应用程序产生这样错误时导致整机陷入不可恢复的境地。对于 Windows 来说,OS 将这类违例包装为所谓的结构化异常(SEH),用户程序可以通过特殊的 __try..__catch 关键字来拦截 SEH,而 Linux 或者其他 POSIX 兼容的系统则是抛出 SIGSEGV 或者 SIGBUS 等等信号,应哟程序可以通过 signal(SIGSEGV, handler) 这样的系统调用来拦截特定的 signal。
无论是上面提到的 Null 指针类似的哪一种情况,通常都是抛出 SIGSEGV 信号。所以我们应该是这样去拦截它的:
1
2
3
4
5
6
7
8
9
10
11
t1 += sub_cmd{}("ssi", "ssi", "access-ileggal-address")
.description("causes a segfault and hook it via linux signal()")
.group("Test")
.on_invoke([](cmd const, string_array const &) -> int {
// cmdr::debug::UnhandledExceptionHookInstaller _ueh{};
cmdr::debug::SigSegVInstaller _ssi{};
int *foo = (int *) -1; // make a bad pointer
printf("%d\n", *foo); // causes segfault
return 0;
});
同样的,Line 6 负责安装拦截器,如果有必要,你可以提供一个额外的 lambda 函数作为拦截器的响应函数,替代默认的版本。但默认版本会打印出栈帧信息,虽然不能提供足够完美的信息,但也是相当有用了:
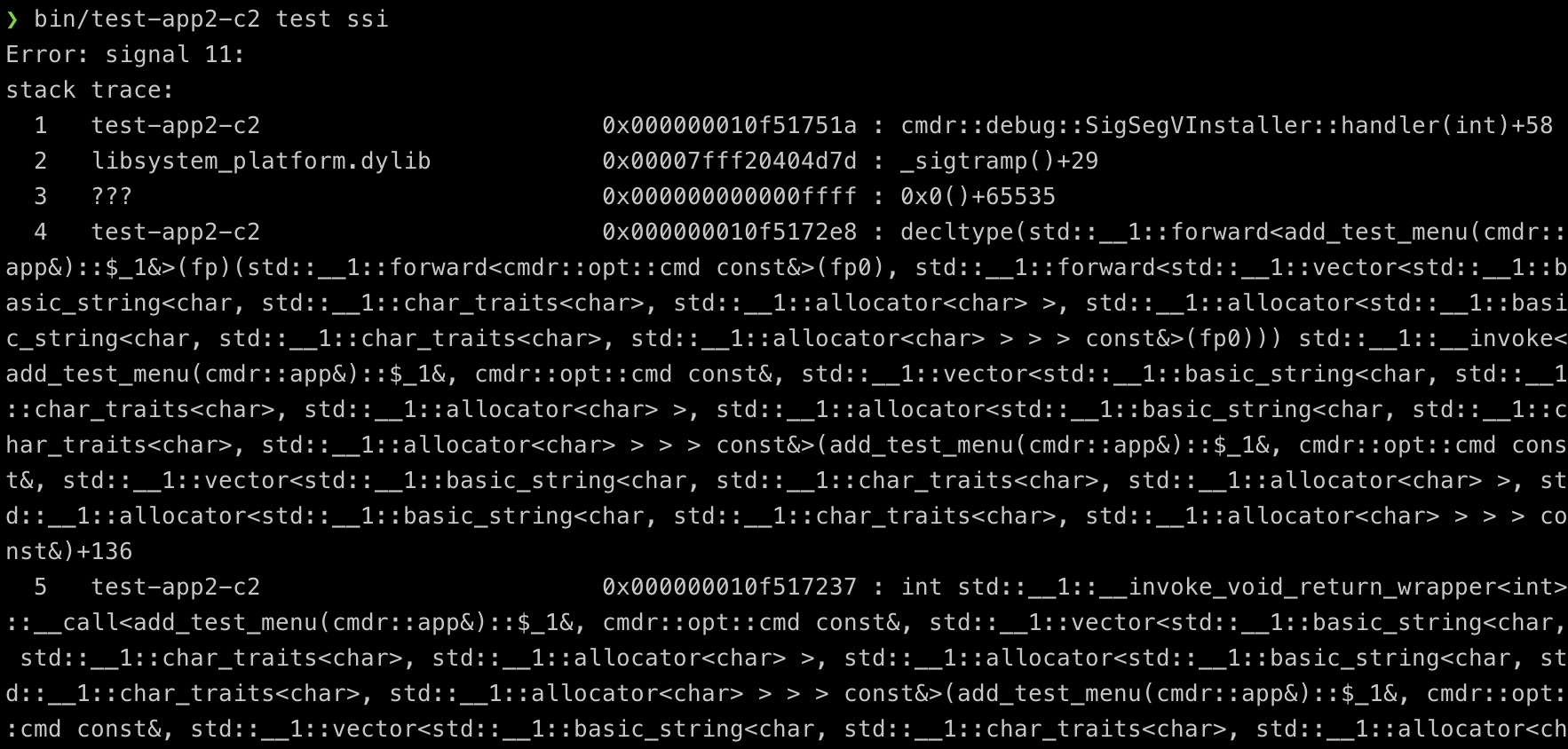
更多
以后再补充吧
cmdr::debug
在上面我们都是基于 cmdr::debug 名字空间中提供的简化手段来阐述和异常相关的各种内容的。
在 cmdr::debug 中,除了 UnhandledExceptionHookInstaller,SigSegVInstaller 之外,还有 SignalInstaller<sig> 等等工具。不过暂时还没有针对 Windows SEH 做一个相应的包装,也许将来会的吧。
实际上,这里会涉及到除了如何拦截异常的问题之外,还要包括:
- 怎么附着行号信息
- 怎么输出拦截到的异常位置的行号信息
- 怎么输出栈帧
- 怎么解释C++符号名,也就是所谓的 demangle 问题
- demangle symbol name 之后,还存在着怎么简化 STL 类名问题
这些问题,一部分在 cmdr::debug 中已经解决,一部分没那么完美但好歹是做了,也有一些还没有处理的。
遗留的问题就要等待将来了。
cmdr::debugnamespace 是cmdr-cxx的一部分。
行号信息为什么这么重要?
因为在嵌入到 IDE 的 Terminal 中,或者 IDE 的 Run/Consol 面板中,文件名加上行号的文字能够被点击和直达对应的源代码,这在排除故障时有多么重要,只有码农才会懂。
所以无论是 exception 抛出,还是 logging 输出,我们都强调应该自动带有行号信息,那样的话,即使你没有在 IDE 环境中,拿到文件名和行号信息也能够大大地提供寻找问题原因的方便性。
所以在 cmdr::debug 中,尝试采用一个包装过的 cmdr_throw_line(arg) 宏来负责抛出异常,你应该在代码中用它代替你的 throw xxx,这样就可以透明地附带行号信息了。
1
#define cmdr_throw_line(arg) throw cmdr::exception::cmdr_exception(__FILE__, __LINE__, arg)
cmdr_throw_line 差不多就是这么做的。
然后我们才能在需要的地方输出行号信息。
更规范地缓存行号信息
类似地,我们也在一个超级轻量的 logger 处采用了类似的策略:这会稍微复杂一点,但整体上也很简单,首先是通过构造函数缓存行号信息,然后通过 operator(...) 去实现 logger 所需的格式化输出,最后在一个宏中包装上面两点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
namespace cmdr::log {
class holder {
const char *_file;
int _line;
const char *_func;
public:
holder(const char *file, int line, const char *func)
: _file(file)
, _line(line)
, _func(func) {}
void operator()(char const *fmt, ...) {
va_list va;
va_start(va, fmt);
xlog().vdebug(_file, _line, _func, fmt, va);
va_end(va);
}
private:
static detail::Log &xlog() { return detail::Log::instance(); }
};
}
#if defined(_DEBUG)
#if defined(_MSC_VER)
#define cmdr_debug(...) cmdr::log::holder(__FILE__, __LINE__, __FUNCSIG__)(__VA_ARGS__)
#else
#define cmdr_debug(...) cmdr::log::holder(__FILE__, __LINE__, __PRETTY_FUNCTION__)(__VA_ARGS__)
#endif
#else
#define cmdr_debug(...) \
_Pragma("GCC diagnostic push") \
_Pragma("GCC diagnostic ignored \"-Wunused-value\"") do { (void) (__VA_ARGS__); } \
while (0) \
_Pragma("GCC diagnostic pop")
#endif
感谢上帝,由于现在已经有可变参数宏了。所以我们的代码可以规范得多。很多年前同样的这一套代码,思路还是相同的,但因为没有可变参数宏,所以我们只能通过不带参数的宏名字来达到同等目的:
1
2
3
4
5
#define OUR_DEBUG cmdr::log::holder(__FILE__, __LINE__, __FUNCSIG__)
// ...
OUR_DEBUG("it's buggy for %s", something);
它能够非常好的工作,只不过我一直觉得不舒服,因为这玩意太残缺了。
当然了,现在我们的版本就很完满了。
我们的 log 是一个脱离外部依赖的超简单版本,它不具备 fmtlib 那样强大而且 C++ 思路的格式化手段,也没有打算借助 C++2a 的 fmt 能力。但是它仍然是完满的,因为 cmdr 中这样的 log 功能足够了。
REFs
-
https://stackoverflow.com/questions/691719/c-display-stack-trace-on-exception
-
https://panthema.net/2008/0901-stacktrace-demangled/
-
https://www.gnu.org/software/libc/manual/html_node/Backtraces.html
-
https://stackoverflow.com/questions/32884628/abi-cxa-demangle-cant-reuse-memory-returned-by-itself
-
https://stackoverflow.com/questions/281818/unmangling-the-result-of-stdtype-infoname
-
https://stackoverflow.com/questions/12227640/simplifying-complex-c-template-symbols
STLFilt could help you. There are two perl scripts, STLFilt.pl (for Visual C++) and gSTLFilt.p (for gcc). It’s designed to be used for error messages simplification, but I’ve already used it for postprocessing __cxa_demangle’s output.
Conclusion
行号是调试利器
C++ 无法实现如同 Java/Golang 那样的每一栈帧的行号信息。甚至于提取到故障点的行号信息也不是那么容易。
其实是 GCC 以及 execinfo 不能在栈帧中提供足够的符号信息问题。
宇宙最强IDE—VS
Visual C++ 针对这样的问题有自己的解决思路,从 VC6 起他们就提供 pdb 文件以及符号信息,不但可以定位栈帧中的一切符号信息和行号信息,甚至还能做到就地 apply。
什么叫做就地 apply?这是 Visual C++ 独此一家的独门绝技,在调试断点到某个位置时,你可以小小地修改一下上下文的代码,或者哪怕是其他源文件中的不相关代码也可以,然后使用菜单命令 Apply Changes,Visual Studio IDE 就能就地编译然后将二进制机器码热更新到你的暂停点位置,上下文的一切内容只要有可能,统统保持原样。
经常是,我们设定一个断点,然后运行并暂停到那里,检查运行中的上下文中变量的值,根据需要修订一下后继的源代码例如条件分支的表达式等等,然后就地应用,继续跑调试应用。这样的情况下,我还需要什么 Unit Tests,全都弱爆了好不好?
这当然只是一句吐槽而已
这样的魔法操作,只有 VC6 的那一堆人才会有这样的创意,而且还能将它给实现了。任何懂点编译原理的人都能晓得在调试状态下热更新代码还要保持栈帧上下文的难度,所以那堆人都是魔鬼。
这还不是全部,VS IDE 变态到什么地步?你可以在断点到某个地方之后,后悔一下:你可以通过“回退执行”或者说叫做“反向执行”的方法退回上一条语句。这是可以多次操作的,如果没有其他意外阻止,你甚至能会退到函数的调用者,乃至继续回退到调用顶层——当然,由于现实的代码结构通常很复杂,而且存在多线程运行的情况,实际上你是不太可能退回到 main() 的,但那又如何呢?能够会退三条语句,有时候就是代表着节省了2、30分钟了。
所以 VC/VS 是宇宙最强 IDE,真的是绝非浪得虚名。
现在好久没开过 Visual Studio 了,甚至都没有安装它,因为太巨大了,完整安装 VS 2019 可能需要上百G,我记不清了,但印象似乎没什么错,你要是安装 VC,MFC,SQL Server,各种版本的 Windows Platform SDKs 以及 DDKs(现在已经没有单独的 DDK 了,不过这个概念还是存在的,无非是 WDM 开发需要的那堆东西),我还没有说 VB,VF,以及疯狂的 .NET/C#,更没有说到 Xarmanri 那一堆,反正上百 GB 是真的需要的。你想说我不需要安装这么多,可以裁剪可以选择的。即使如此,那也是几十 GB 吧,什么时候几十 GB 就这么没牌面了?搞虚拟机的 Parallels 的人会说几十 GB 它也不小哇。
言归正传,提供符号信息并不是 Visual C++ 的专利,gdb、lldb 同样也可以,这都是标配。
代码是“变”好的,除非你不去“变”
我们的代码总是在不断地试探和总结中变得越来越好——Why?因为我们会去读自己写的代码,会去思考,会去研究能不能让伙伴受益。
如果没有这样的道德基础,那当然是可想而知的。
就这样吧。

留下评论