
序言
很早以前,我有计划要为 GTD 做一个定时报闹的库,原因在于大多数现在的 GTD 软件、TODO、行事历等等全部都不能给我足够好用的定时器。确切地说,是所有的它们都不行。
Google 集成在 Gmail 中的 Task 可能是相对来说最好的一个了,因为它支持农历(我记得好像如此,但不确定了)。但是很显然它并不支持 冬至之后 105 天 这样的定义。
当然,我们当前的目标也不包括上述这一能力,因为农历计算存在着很多难解的问题,而且闰秒问题现在也悬而未决,所以对于农历的支持我们的目标中暂时挂起,留待今后补全。
目标 (Ticker & Timer)
0820
0825
0901
1031
1104
一个 timer 给定了对某个确定时间点的表述,类似的,它具有两个关键要素:
- 定点性
- 异步性
一个 ticker 给定了对某个周期性事务的表述,它具有三个关键要素:
- 定点性
- 异步性
- 周期性
所以,在设计层面上,我们不应该混合这两者。不过,既然他们具有一定的继承性,那么我们完全可以在一个完美的 timer 上增加 周期性 来做到糅合,这也是我们所期望的设计结果。
一般地,这两者的综合体习惯上被称作 Scheduler。
接下来我们的首要任务就在于要去试图架构出一个完美的 timer 作为一切的基础。
完美的 timer 基础
所谓的完美在于:
- 精度达到 ns 级别
- 无限制的大批量 timers 可以被随意创建,自由调度
- 完善的 thread pool 支持,充分解耦
在底层选择上,自然是选择以 C++17 向后,因为我们以前也提到过,从 C++17 之后才开始具备了 pure c++ 跨平台能力,当然这是一个有软件开发洁癖的人的说法,否则这几十年来 wx,qt,boost 等等类库难道都那么差?自然不是的,我们只是在说,pure c++ 现在才有了可能性,不必引用 OS APIs、也不必考虑太多 OS Features、也不必引入 POSIX APIs 去掩盖操作系统特性,仍能做出较好甚至是具备充分完整支持的跨平台类库。
进一步的目标
我长期使用 GTD 工具或者行事历相似的 apps。迄今为止,那些个宣称自己最 NB 的 GTD apps,无论哪个平台(macOS,Windows,Web,Mobile)中,它们都没有达到我的要求:
- 我只提一个要求——关于周期的设置问题,其他的就算了:
- 每个月倒数第三天
- 12 月的第二个星期日
- 2-29 逢闰年
- 每年第 43 周
- 农历生日
- 农历节气
如上,你可能找不出哪个 GTD 具备上述的周期设置能力。如果你知道有,何不 tip 我。
所以,我计划实现的这个库将会准备实现上述的这些形态各异的周期指定方法。不过由于 c++17 对历法的支持有限,所以少部分的特性(例如农历方面的)只能延后到 c++20 成为工程主流后再考虑实现了(或者稍后我有精力研究历法问题时)。
如前所述,农历与节气问题暂且搁置。
背景知识
为了评估我们想要达到的 ns 精度,有必要回顾一下时钟、定时任务等概念在各种层面的实现先。大概有这么一些情况。
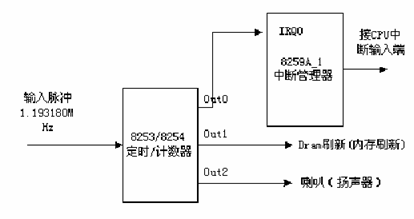
晶振,8253 定时器/计数器 与 8259A 上的时钟中断
这是挺古老的东西了,它是 IBM PC Compatible 规范的产物之一。计算机上的一切计时工具,无论是实时时钟也好、闹铃也好,还是你正在使用的 GTD app 也好,追根溯源都是由它发出的时钟脉冲所衍生出来的。此外,CPU 的运转也有赖于从这里获得的 tick 演变出的时间片、时钟周期来决定每条指令会消耗多少算例。
在新时代,各种不同的计算设备也都依赖同样的晶振核心以及一个定时计数也达到同样的效果。
BIOS 中断
在 CPU 得到了时钟激励并开始运转之后,8259A 向 BIOS 提供硬件信号,这就是所谓时钟硬中断(8259A 还提供可编程的软中断,这里就不提了),它是 BIOS 所获得的少有的硬件中断之一。
顺便一提,实时操作系统以及实时系统之所以有别于电脑、手机等常规性民用设备,就在于它们有更多的硬件中断,并能够在 OS 内核中正确地处理这些中断任务。所以一般来说由 Linux 改造出来的所谓 rtLinux 并不被认为是真正的实时操作系统。
OS 中断、陷阱与陷入
OS 按照自己的设计目标来选择接管 BIOS 中断,或者完全抛弃 BIOS 并自行提供全面的中断服务(如果想要提供真正的争先式内核的话)。
以 Linux 为例,它选择了抛弃 BIOS 支持,并完全接管了包括时钟中断在内的所有硬件设备信号管理器。在时钟管理上,Linux 早期采用了简易的时间轮技术来提供包装过后的定时器任务服务,并在此基础上提供了 at 命令和 cron 服务,其弱点在于只有 ms 精度,并且理论上说可控管的定时器有限。随着 Linux 的不断迭代以及硬件升级,在需要更强大、更大规模、更高精度定时器管理器的需求推动下,又有更优秀的设计实现(多级时间轮,红黑树或最小堆)。
Timing Wheel
时间轮算法历史悠久,其创意带有经典的 C 工程师思维风格。
在时间轮上,尤其是多级时间轮算法思路上,从概念上来说,大抵是按照 day,hour,minute,second,millisecond 的方式建造级联的轮级:
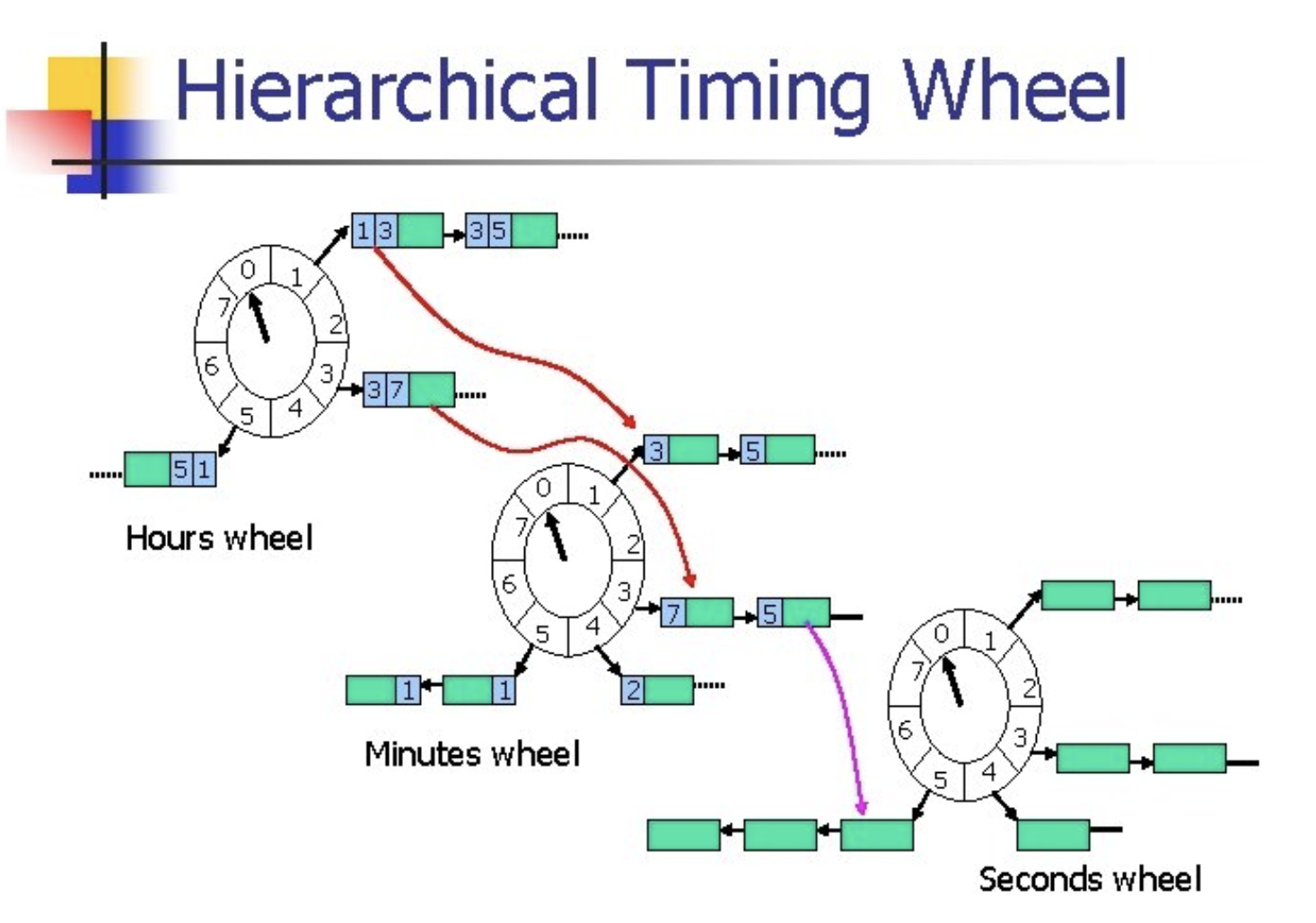
也可以略微调整数据结构,例如使用时分秒数值做相应的 slot,使用 unix time value 做 hash 计算后建造一个单一的时间轮,或者改用 Tree 结构,等等。
参考
源头的激励方式
前文中已经提及了硬件中断及其 BIOS 和 OS 层面的包装。所以我们知道,归根结底,时间轮也好,二叉树也好,我们所实现的 timer 必须有一个恰当的时钟源进行恰当的激励,才能推动 timer 的运行。
tick+loop
一种办法是 tick+loop,每个 TICK 就检查有无到期的 bucket,我们想要实现 ns 的精度,则设定 TICK 为 1ns,在一个循环中进行检测。这种办法其实很明显地精度偏低,你可以用在 ms 精度级别,但用在 ns 级别会带来极大的损耗,白白浪费 CPU 算力,因为这频率未免太高了。
event-driven
另一种办法是 事件触发方式,例如借助 OS 包装后的高精度 timer,在给定的时间点 wake up,并检查该时间点的 bucket 中有哪些 tasks 并进行激励即可。这种方式(setitimer),只要你有节制地使用,那么它可以相对地大幅度地节省算力,也可以足够及时地激励任务。必要时,可以将任务通过消息队列分发到其他计算节点来保证高频任务到及时处理。
在这里,比较容易眩晕的是,OS 的高精度 timer,其实也是实现的相似的算法(Linux 2.6.16+ 的 setitimer),为何我们还要实现一套 timer 呢?其实这是因为 setitimer 的回调机制是 SIG_ALARM,这显然是不合规的(对于 pure c++来说),所以我们必须进行重复实现,不但要解除 SIG_ALARM 的竞争问题,也要将其转换为 c++ 的 std::function 方式。
此外,这只是一种简单的描述,事实上我们并不会选择 Linux API 方式的激励,而是采用 POSIX 所提供的 API 来完成这个任务。原因更简单,POSIX 接口相对来说更具备跨平台性,我们可以在几乎所有的 Unix,BSD 系上跳过兼容性测试。
1
2
3
4
5
int timer_create(clockid_t clock_id, struct sigevent *evp, timer_t *timerid);
int timer_settime(timer_t timerid, int flags, const struct itimerspec *value, struct itimerspect *ovalue);
int timer_gettime(timer_t timerid,struct itimerspec *value);
int timer_getoverrun(timer_t timerid);
int timer_delete (timer_t timerid);
现在就只剩少量的问题了,例如 windows 平台,android 平台,以及未来的 OS 们。这其中,我们可以选择搁置先。其中对于 windows 来说,我们可以选择采用 QueryPerformanceCounter 做 us 级别的兼容实现。它的缺点除了精度稍低之外,还有就是需要通过延时循环来间接实现定时器,稍稍有点浪费算力。
sleep+loop
综合来看,采用 tick+loop 的方式,相对误差较大,一定程度上较为浪费算力。而事件触发机制的相对误差略小,重点在于非常节省算力,问题在于跨平台实现需要多伤脑筋,且不一定能够得到充分兼容的跨平台实现。
所以还有第三种方式:sleep+loop。
这种方式是在第一种方法的基础上调整时间轮结构,将所有任务的时间点排序,计算下一任务的时间点所需要的延迟并 sleep 直到到点,激励,然后循环处理下一次任务到时间点,如此往复。
所以我们不再需要硬件层面的时钟激励了,避开了事件激励方式的跨平台难题。这时,计算量比事件方式要大一点,但远小于 tick+loop 的方式。
这也是我们最终选定的实现方案。稍后我们将会进入实作环节。
由于 sleep 与 loop 等内务导致的相对误差较大,所以尽管从 API 层面上我们能够支持 ns 级别,但实际上使用者不宜建立低于 100ns 的任务,因为此时的 missed task 可能性会大幅度增加,此外另一副作用是 CPU Usage 将会明显地飙升。
事实上,我们不建议低于 ms 级别的任务提交(针对一般的家用或服务器场所),除非你是在为专用板卡进行开发。
由于这个库是面向 GTD 工具做支持的,所以不被 ms 级别限制而制约。
遗留问题
每一次计划要做的类库,总是不完美,总会有这样那样的问题发生,总是会放弃一些什么。这次也不例外,至少下面的问题是尚未处理的,需要找到一种惯例之后才能考虑应该如何解决它们,所以目前来说,如果它们是你的问题,你需要解决它们:
-
当系统时钟被修订之后,你必须刷新时间轮吧?
-
如果操作者频繁修改系统时钟的话,刷新时间轮会不会将其弄崩溃?
-
最好的办法是不必消除过期任务,采用一个“自然地”选择算法来略过它们即可?但这不会带来庞大的内存消耗吗?
世间安得双全法啊!
实现
原本打算首先在 hicc-cxx 中实验:hz-ticker.hh (BROKEN)。此外还计划将其正式版迁移到 cmdr-cxx 中,我们提到过,通常 cmdr-cxx 才是正式的发布点。
但是最终我们打算单独发行这个库:ticker-cxx。
已达到的目标
实际精度
不得不说,ns 精度可能是个尚不现实的目标,我们只能够逼近它。
由于任务切换,调度器自身内务均需要消耗时钟周期,因此我们所实现的 timer 只能在理论上达到 ns,实际上在测试用例中我们可以逼近 200ns 甚至 100ns。所以对于实际工程运行时,我们认为的精度:
- 不宜低于 us(微秒,microsecond)级别
- 也可以在充分优化后采用 500ns 甚至更小(甚至到 200ns)。
这里所说的精度,代表着最小的下一任务的间隔。由于你可能构造 N 个可重复的定时任务,所以实际的精确度有可能更受限制——不能排除少数极端情况下的任务的被调度信号丢失的情况,如果下一任务的间隔充分小的话(例如数 ns 以至于立即触发)。
不过,如果你只关心 us/ms 级别的周期任务,或者你在做 GTD 类似的周期(他们通常都是 day 级别的)任务,那么上面所说的限制不会阻碍你。
前文中提到过不推荐
快于 ms 级别的任务,虽然目前的测试表明理论上我们可以支持到数百 ns 或者 1us。不要
快于 ms 级别依然是我们出于保守目的给你的建议。
OS/Compiler 限制
std::chrono::system_clock 精度是受到 C++ 编译器和 OS 双方面的综合制约的,能够肯定的是在 linux 上 llvm 和 gcc 均提供 nanosecond 精度。
请注意,std::chrono::system_clock 是 wall clock(壁钟),它才有日期的概念。而 std::chrono::high_resolution_clock 是 steady clock(单调时钟),它是一种开机后的 ticks 计数值,适用于时间段的计量,但没有日期和历法的概念,也不能被修改。
综合第看几种主流 OSes(darwin/windows/linux),它们支持的最小精度为 us,而像 linux 或者 windows 则能够在硬件充分的前提下支持到 ns。
少量解说
timer class
如前所述,我们首先建立了 timer 这个类,它提供 in/after,at 这两个语义。相应的实现节选如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
template<typename Clock = Clock>
class timer {
template<typename _Callable, typename... _Args>
timer &in(const typename Clock::time_point time, _Callable &&f, _Args &&...args) {
UNUSED(time, f);
std::shared_ptr<Job> t = std::make_shared<detail::in_job>(
std::bind(std::forward<_Callable>(f), std::forward<_Args>(args)...));
add_task(time, std::move(t));
return (*this);
}
template<typename _Callable, typename... _Args>
timer &in(const typename Clock::duration time, _Callable &&f, _Args &&...args) {
in(Clock::now() + time, std::forward<_Callable>(f), std::forward<_Args>(args)...);
return (*this);
}
template<typename _Callable, typename... _Args>
timer &after(const typename Clock::time_point time, _Callable &&f, _Args &&...args) { return in(time, f, args...); }
template<typename _Callable, typename... _Args>
timer &after(const typename Clock::duration time, _Callable &&f, _Args &&...args) { return in(time, f, args...); }
template<typename _Callable, typename... _Args>
timer &at(const std::string &time, _Callable &&f, _Args &&...args) {
UNUSED(time, f);
std::tm tm;
// our final time as a time_point
typename Clock::time_point tp;
if (hicc::chrono::try_parse_by(tm, time, "%H:%M:%S", "%Y-%m-%d %H:%M:%S", "%Y/%m/%d %H:%M:%S")) {
tp = hicc::chrono::tm_2_time_point(&tm);
// if we've already passed this time, the user will mean next day, so add a day.
if (Clock::now() >= tp)
tp += std::chrono::hours(24);
} else {
// could not parse time
throw std::runtime_error("Cannot parse time string: " + time);
}
in(tp, std::forward<_Callable>(f), std::forward<_Args>(args)...);
return (*this);
}
};
这组语义的创意来自于 Bosma/Scheduler 和 Rufus-Scheduler gem,并且这两个谓词实现的机理也参照了 Bosma/Scheduler。
它们主要是用到了完美转发来打包用户的任务,然后调用 add_task 将任务的首次触发的时间点压入时间轮中。
由于时间轮中总是处在等待下一次任务的 sleep 中,所以如果你添加了一个这之前的(小于下一任务的时间点)的任务的话,它将永远不会有效。所以你需要在添加任务时注意避免。
调用
使用的方法类似于这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
void test_timer() {
using namespace std::literals::chrono_literals;
hicc::debug::X x_local_var;
hicc::pool::conditional_wait_for_int count{1};
hicc::chrono::timer t;
{
auto now = hicc::chrono::now();
printf(" - start at: %s\n", hicc::chrono::format_time_point(now).c_str());
}
t.after(100ms, [&count]() {
auto now = hicc::chrono::now();
// std::time_t ct = std::time(0);
// char *cc = ctime(&ct);
printf(" - after [%02d]: %s\n", count.val(), hicc::chrono::format_time_point(now).c_str());
count.set();
});
count.wait();
// t.clear();
}
它会有一次性的 job 触发:
1
2
3
4
...
- start at: 2021-08-21 03:31:11.595601
- after [00]: 2021-08-21 03:31:14.597016
...
ticker class
Ticker 会实现 every,interval 谓词。every 是周期性重复的 job,interval 与其相似但会就地立即触发一次(但我并不保证)。
注意
由于时间轮中的下一时间点的计算是个小尺度计算,所以它很容易被搞乱。当你真的工作在 ns 级别时,需要非常小心:
-
不要频繁地修改时间轮
这意味着你不应该随时随地地使用 in/after, at, every, interval 等接口添加新任务。
频繁增加任务可能导致某些任务永远也不能够被激发,尽管这可能只是稀少的临界情况。
-
不要制造大量的离散性的定时任务
不要用各种周期(例如这样一组:313ns,,475ns,521ns,660ns)去创建一大堆定时任务,因为它们的离散性将导致很快地交织出一些超级小的下一任务时间间隔(例如10ns),此时时间轮的工作可能不太好,很大概率下一任务的激发事件会因此丢失掉。
我们建议你在成倍数的周期上(例如 500ns, 1000ns,1500ms)堆叠任务。由于相同时间点的任务会被堆叠到时间轮上的同一点,因此这些任务将被安全地激发。
未来我们会考虑支持节气定点和农历定点。
后记
前文已经提到过了,C++17 从标准库的层面上仍然不支持历法功能,所以短期内我们无法添加足够好、足够实用的历法设施到 ticker-cxx 中,也就是说,我们尚未能真正支持夏令时,国际历法组织闰秒,农历等等。
实现一个历法系统是如此的高精尖,以至于甚至没有几个组织能够提供真正的历法库。当然,这已经是另一个话题了。
你可能并不相信,然而事实上是,微软、Apple、Google 这样的提供公共服务的组织,它们的历法支持设施依然是有限的,被动的,有时候可能是有问题的。
然而,ticker-cxx 至少提供了一个可插拔的机制,允许你提供增强的算法以实现相应的支持(你完全可以不必那么完美地、在一定限制条件下实现农历计算支持),所以从这个价角度来说,我们是做到了设计目标的大部分的。
做一个类库,实在是不容易的。
REFs
- ticker-cxx: https://github.com/hedzr/ticker-cxx
- Bosma/Scheduler 和 Rufus-Scheduler
放飞自我
不提 Mask 和 Twitter 了。
现在更值得忧虑的可能还是 WW3 的问题吧。
每当发现有一个什么事不是自己能够控制的,就不由得情绪低落。比如不知道头胎是个女儿还是儿子,又或者几年内会不会 WW3。
如此看来,情绪低落还真忒么容易啊,难怪现在都在讲解决内耗。
![]()

留下评论